Table of Contents
The Internet Engineering Task Force (IETF) published RFC 6749, the core specification of OAuth 2.0, on October 13, 2012. Since then, the OAUTH Working Group of the IETF has continued its work and remains actively engaged in developing new standards.
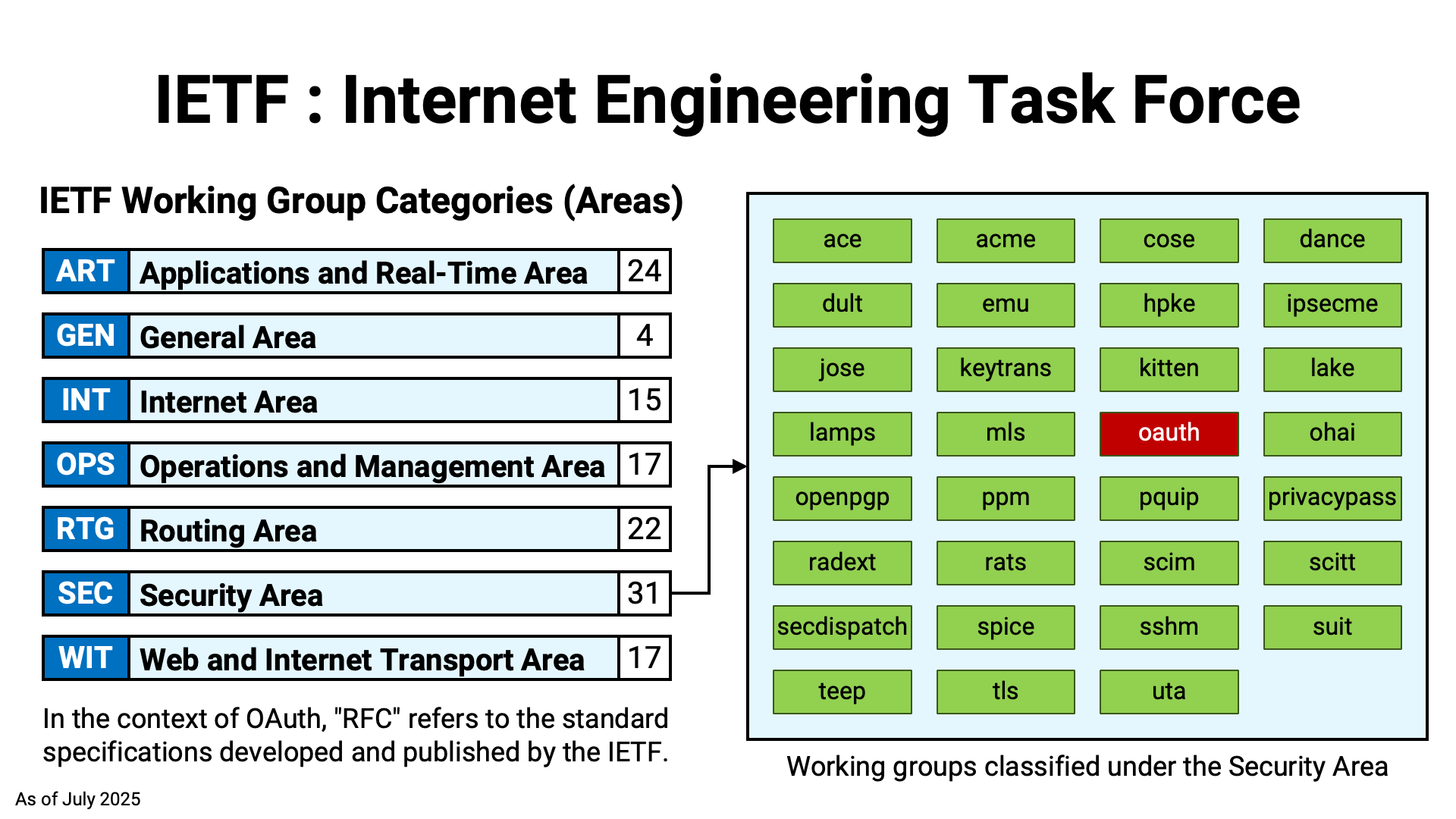
As time has passed, the number of RFCs developed by the working group has increased, now exceeding 30.
On the other hand, the OpenID Foundation (OIDF) published the core specification of OpenID Connect, OpenID Connect Core 1.0, in 2014. The Foundation’s working groups have continued to actively develop new standards ever since.
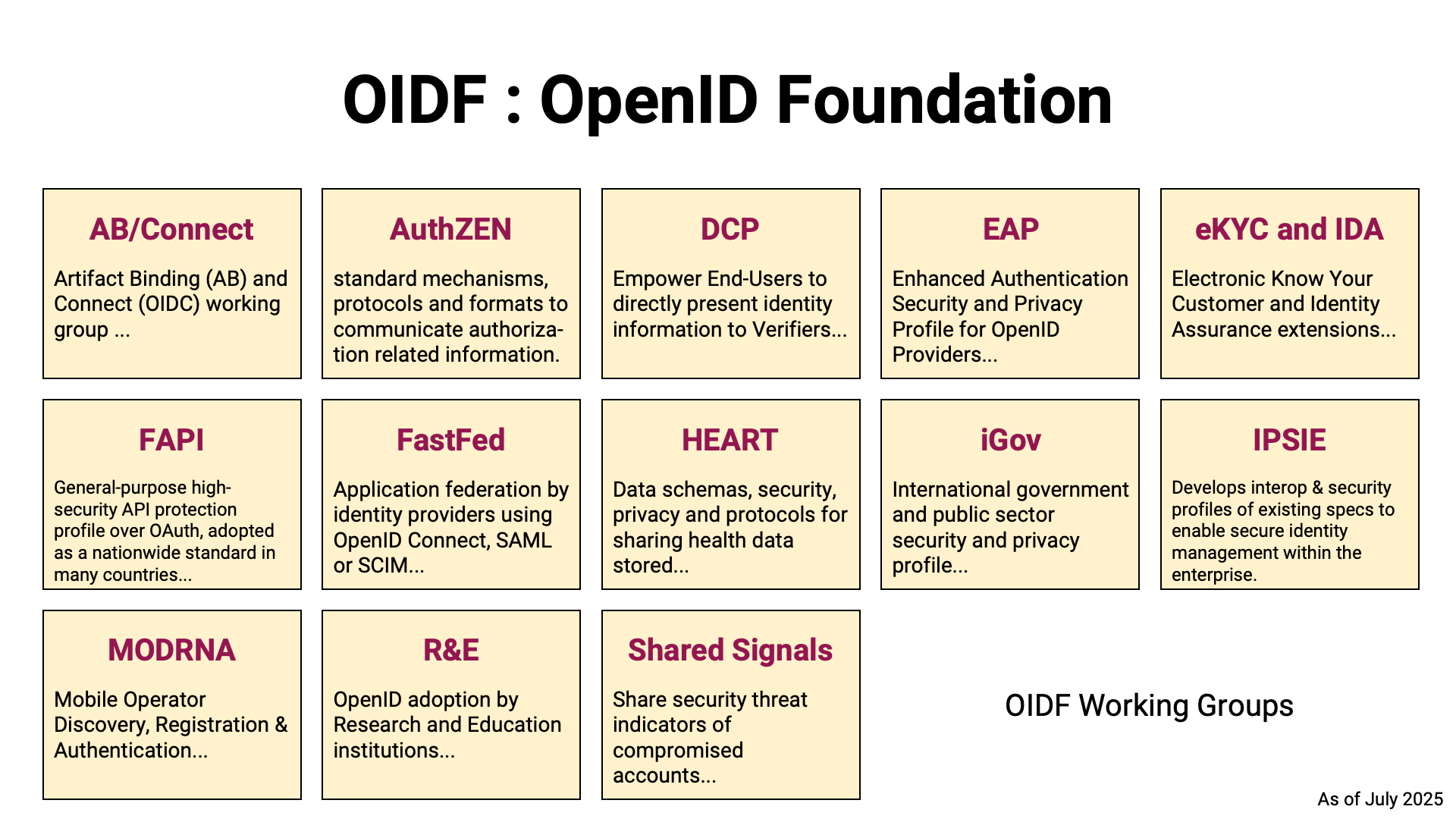
There are also a fair number of specifications that have been developed or are currently being developed by the OIDF working groups.
In addition to these, standards developed elsewhere are also referenced in the context of OAuth and OpenID. For example, the OpenID Shared Signals Framework Specification 1.0 relies on the following RFCs developed by the now-closed IETF’s SECEVENT Working Group:
Similarly, FAPI 2.0 Http Signatures relies on the following RFCs developed by the IETF’s HTTPBIS Working Group:
| Date | RFC | Title |
|---|---|---|
| Structured Field Values for HTTP★ | ||
| HTTP Message Signatures★ | ||
| Digest Fields |
As a discerning reader might suspect, once we start discussing dependencies, there’s no end to it. This is because, in almost all cases, new specifications are built on top of existing ones. As a result, newer specifications generally require a greater amount of prerequisite knowledge to fully understand.
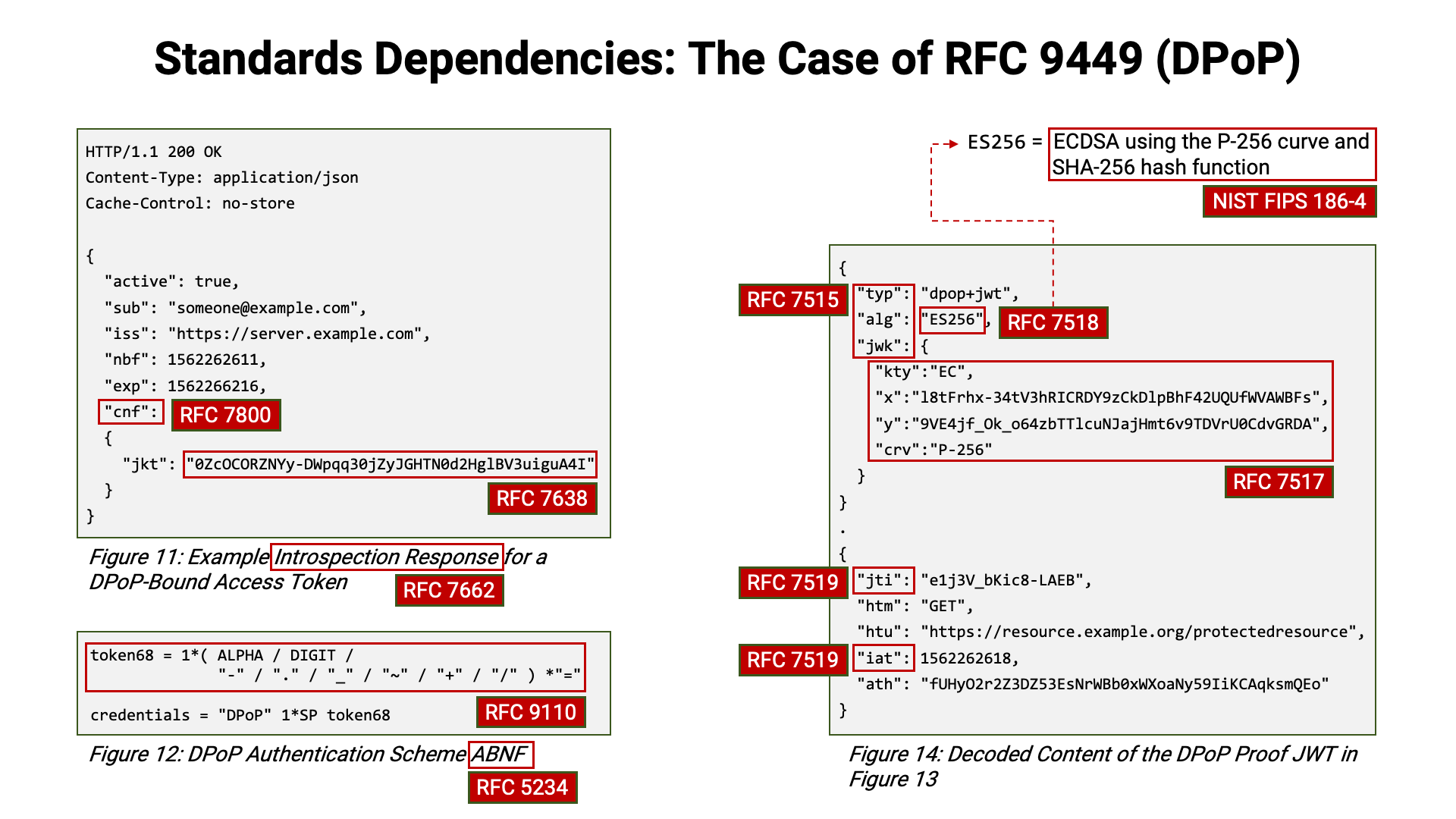
The problem with this situation is that, even when new standards for API protection are published, the high barrier to investigating and evaluating their contents hinders their adoption and use. As a result, the API security of systems that are not proactively updated tends to decline over time in relative terms. Given that attackers continue to evolve in increasingly sophisticated ways, this is a serious concern.
This article introduces how to fully leverage the standards developed since
RFC 6749 to protect APIs. It begins with the basics—using
access tokens (RFC 6750) and retrieving their information
(RFC 7662)—and goes on to cover topics such as audience-restricted
access tokens using the resource parameter (RFC 8707),
sender-constrained access tokens using MTLS (RFC 8705) and DPoP
(RFC 9449), HTTP message signatures (RFC 9421), and
Cedar.
As Authlete is always committed to supporting developers, this article also covers implementation-oriented considerations, such as:
@target-uri
(RFC 9421) when operating behind a reverse proxyLet’s get started!
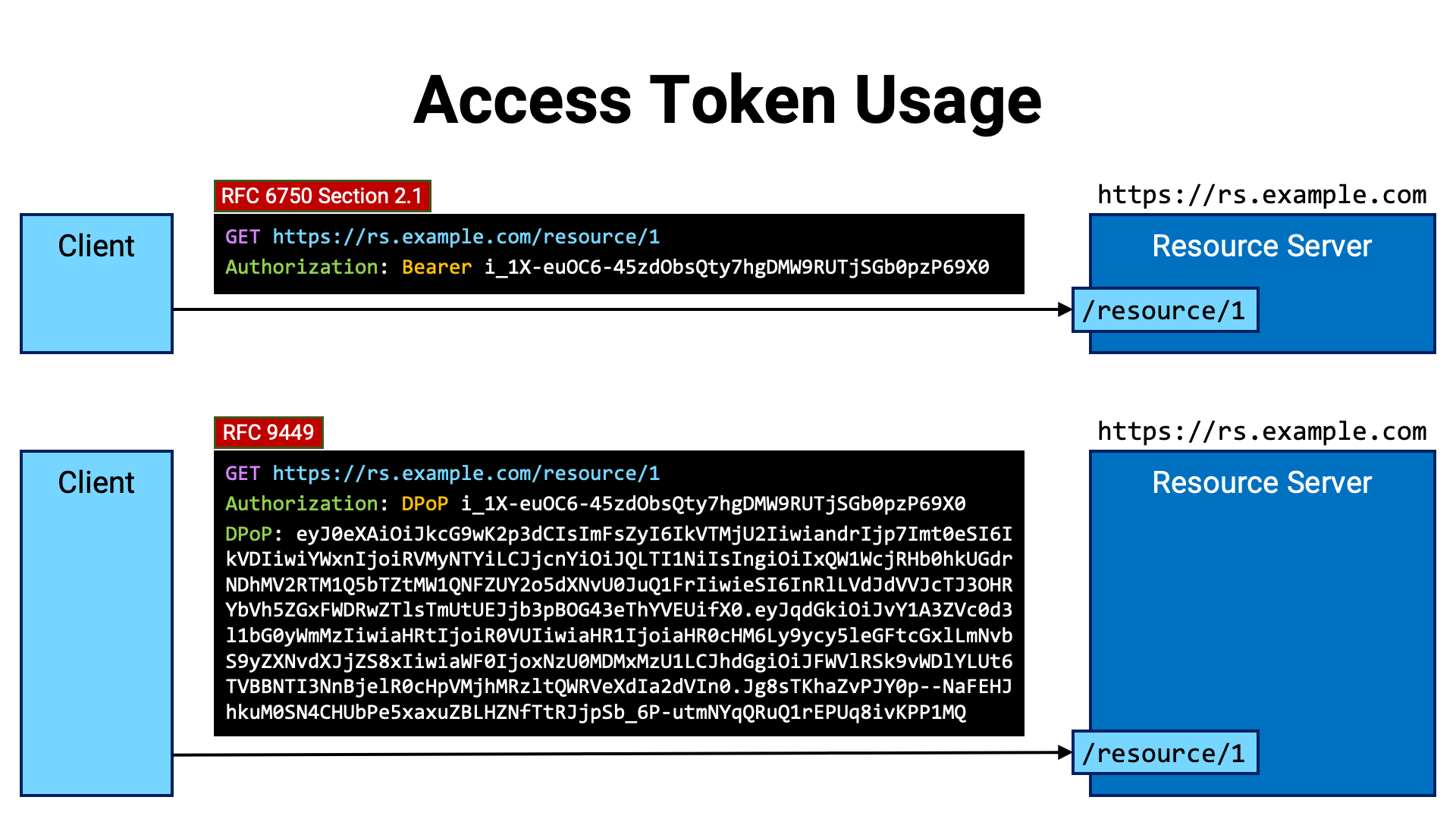
RFC 6750 (Bearer Token Usage) defines three methods for presenting an access token to a resource server:
Authorization header (Section 2.1)However, the second method is rarely used because it restricts the format
of the HTTP request body to
application/,
and the third method is generally avoided due to security concerns.
As a result, the first method is used in most cases.
In the method that uses the Authorization header, the value of the header
is formatted as follows:
Bearer Access Token
Here, the Bearer part is a fixed string, and the Access Token should
be replaced with the actual access token value.
The following is an example of accessing
https://
with the access token
i_1X-euOC6-45zdObsQty7hgDMW9RUTjSGb0pzP69X0.
GET https://rs.example.com/resource/1
Authorization: Bearer i_1X-euOC6-45zdObsQty7hgDMW9RUTjSGb0pzP69X0
When the access token is secured using a mechanism called DPoP
(RFC 9449), the fixed string Bearer is replaced with DPoP.
In addition, a DPoP header must be included. The value of the DPoP header
is a type of JWT (RFC 7519) known as a DPoP proof JWT.
Authorization: DPoP Access Token
DPoP: DPoP proof JWT
The following is an example of accessing a resource using a DPoP-bound access token.
GET https://rs.example.com/resource/1
Authorization: DPoP i_1X-euOC6-45zdObsQty7hgDMW9RUTjSGb0pzP69X0
DPoP: eyJ0eXAiOiJkcG9wK2p3dCIsImFsZyI6IkVTMjU2IiwiandrIjp7Imt0eSI6IkVDIiwiYWxnIjoiRVMyNTYiLCJjcnYiOiJQLTI1NiIsIngiOiIxQW1WcjRHb0hkUGdrNDhMV2RTM1Q5bTZtMW1QNFZUY2o5dXNvU0JuQ1FrIiwieSI6InRlLVdJdVVJcTJ3OHRYbVh5ZGxFWDRwZTlsTmUtUEJjb3pBOG43eThYVEUifX0.eyJqdGkiOiJvY1A3ZVc0d3l1bG0yWmMzIiwiaHRtIjoiR0VUIiwiaHR1IjoiaHR0cHM6Ly9ycy5leGFtcGxlLmNvbS9yZXNvdXJjZS8xIiwiaWF0IjoxNzU0MDMxMzU1LCJhdGgiOiJFWVlRSk9vWDlYLUt6TVBBNTI3NnBjelR0cHpVMjhMRzltQWRVeXdIa2dVIn0.Jg8sTKhaZvPJY0p--NaFEHJhkuM0SN4CHUbPe5xaxuZBLHZNfTtRJjpSb_6P-utmNYqQRuQ1rEPUq8ivKPP1MQ
Further details about DPoP will be provided later.
To validate a presented access token, the resource server must first obtain information about the token.
If the information is embedded within the access token itself, it can be extracted by reading the contents of the token. On the other hand, if the information is not embedded, the resource server must query the authorization server’s introspection endpoint (RFC 7662) to obtain it.
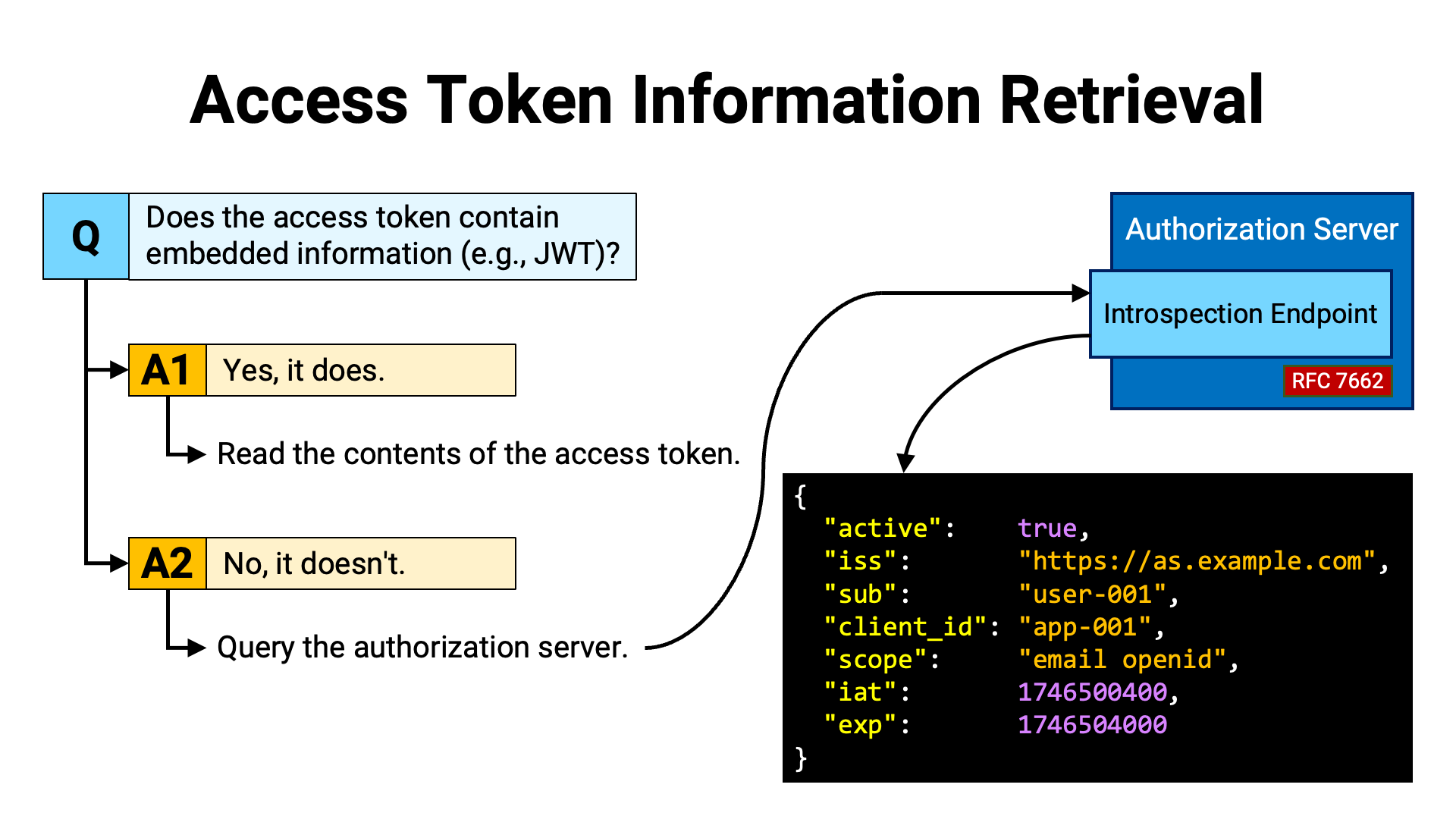
At first glance, embedding information directly into the access token may appear to reduce the burden on the resource server. However, in this format, the server must perform additional work to ensure that the contents of the token have not been tampered with.
When information is embedded in the access token itself, the token format is typically JWT (RFC 7519), since it allows for tamper detection. By verifying the JWT’s signature using the public key of the issuer (in this context, the authorization server that issued the access token), the resource server can confirm that the contents of the JWT have not been altered.
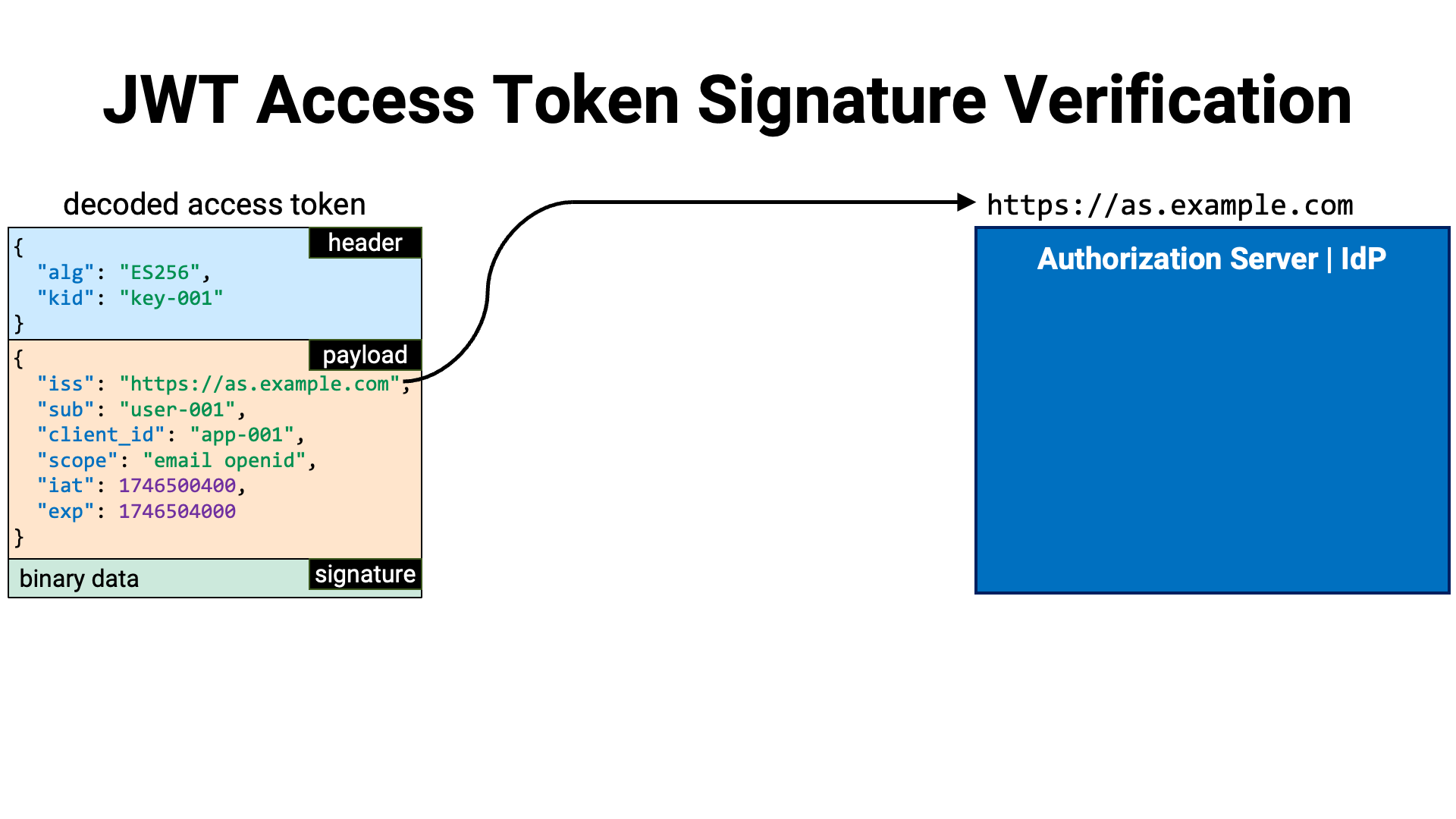
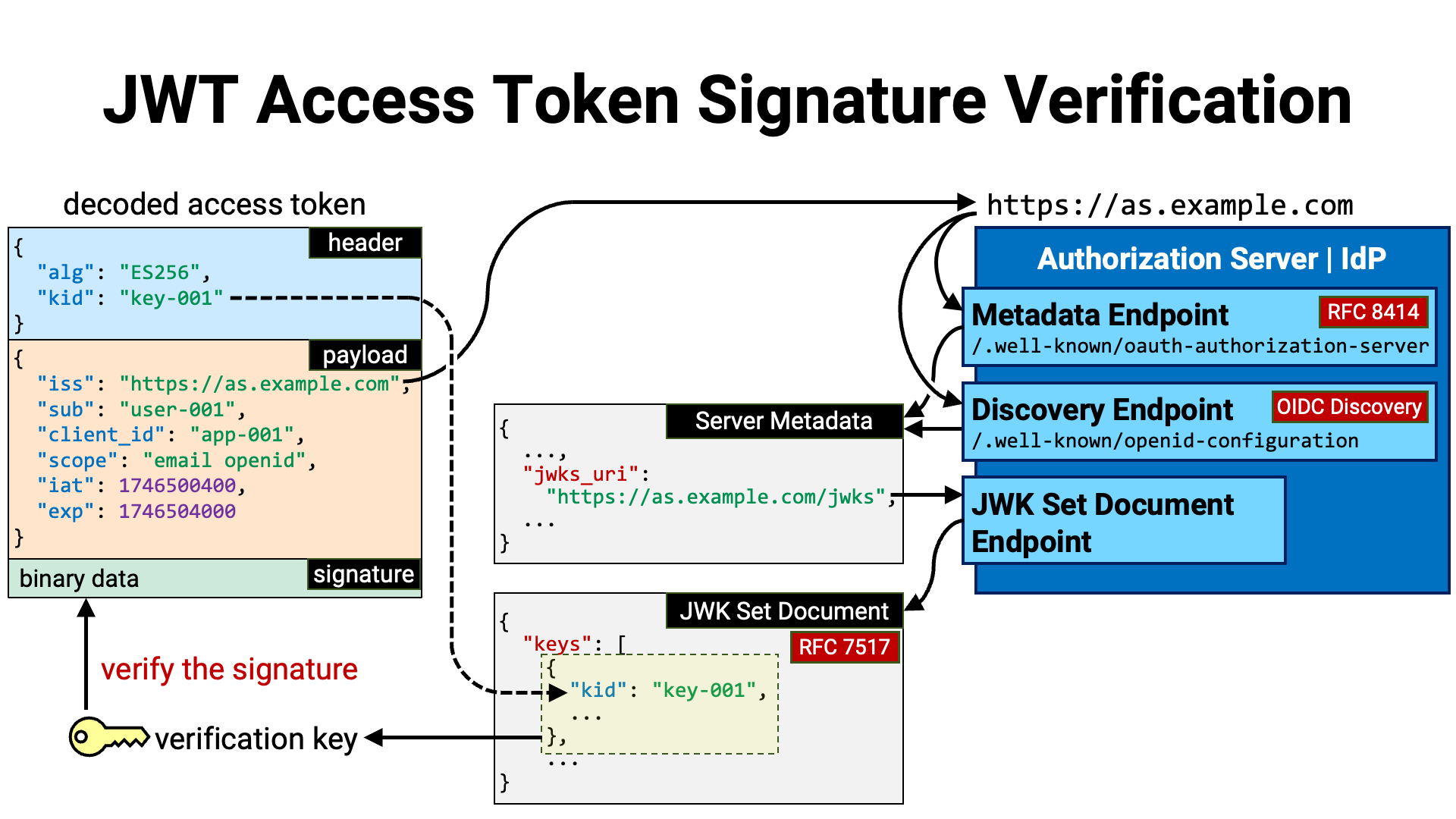
Let’s now walk through the steps for verifying the signature of an access token in JWT format.
First, read the value of the iss claim (RFC 7519 Section 4.1.1)
in the payload of the JWT. This claim identifies the issuer of the JWT. Since
access tokens are issued by the authorization server—or by an OpenID Provider
that also serves as the authorization server—the value of the iss claim in
a JWT access token represents the identifier of the authorization server or
OpenID Provider.
According to the relevant specifications (RFC 8414,
OIDC Core, and OIDC Discovery), the identifier
of the authorization server or OpenID Provider must be a URL starting with
https. As a result, the value of the iss claim is a URL that identifies
the authorization server or OpenID Provider (i.e., an HTTP server) that issued
the access token.
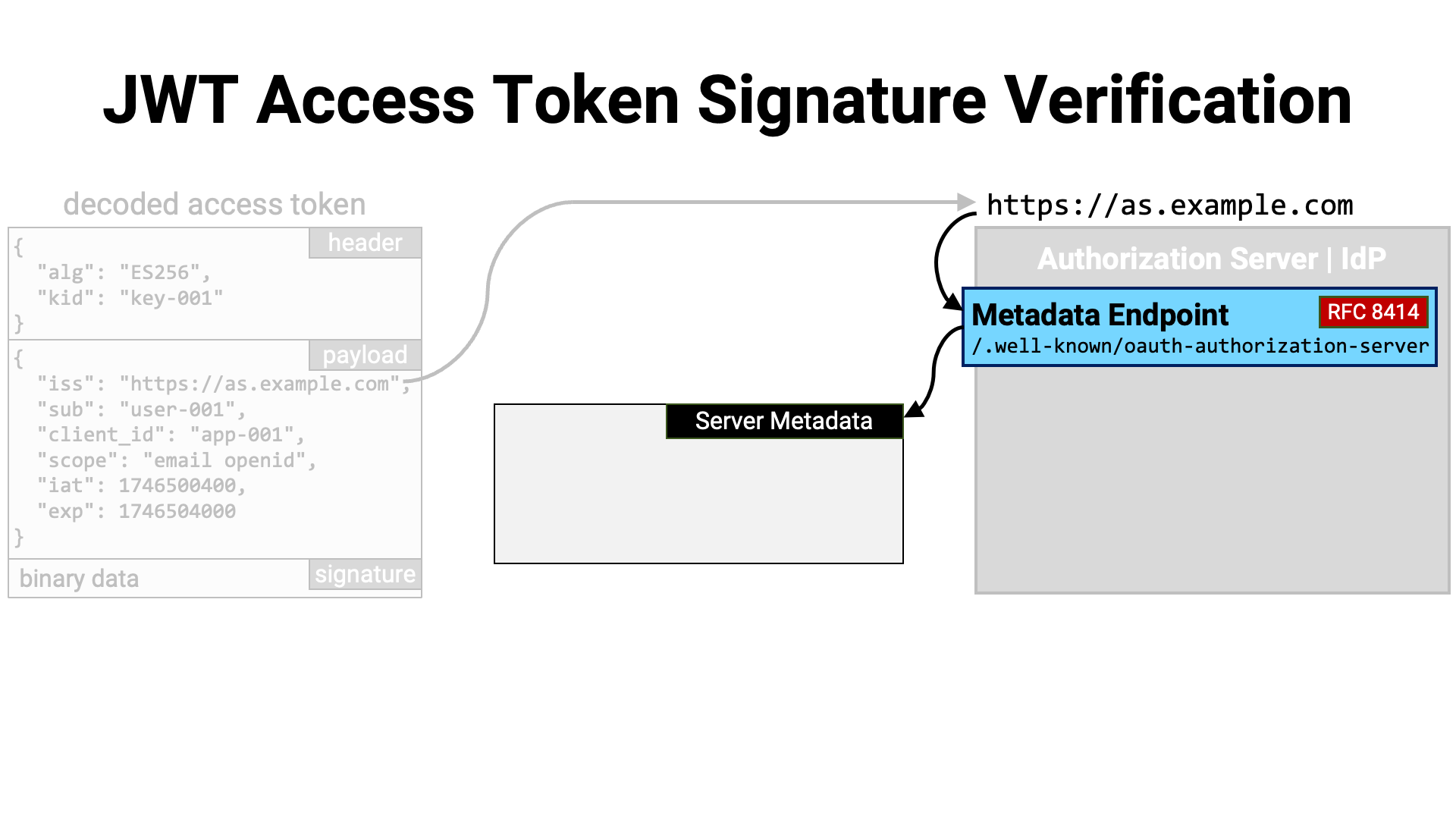
Once the issuer identifier of the access token has been obtained, it can be used to determine where the issuer’s metadata is published.
If the authorization server supports RFC 8414 (OAuth 2.0
Authorization Server Metadata), its metadata is published at the location
obtained by appending
/.well-known/
to the issuer identifier. At this location, the server’s metadata can be
retrieved in JSON format.
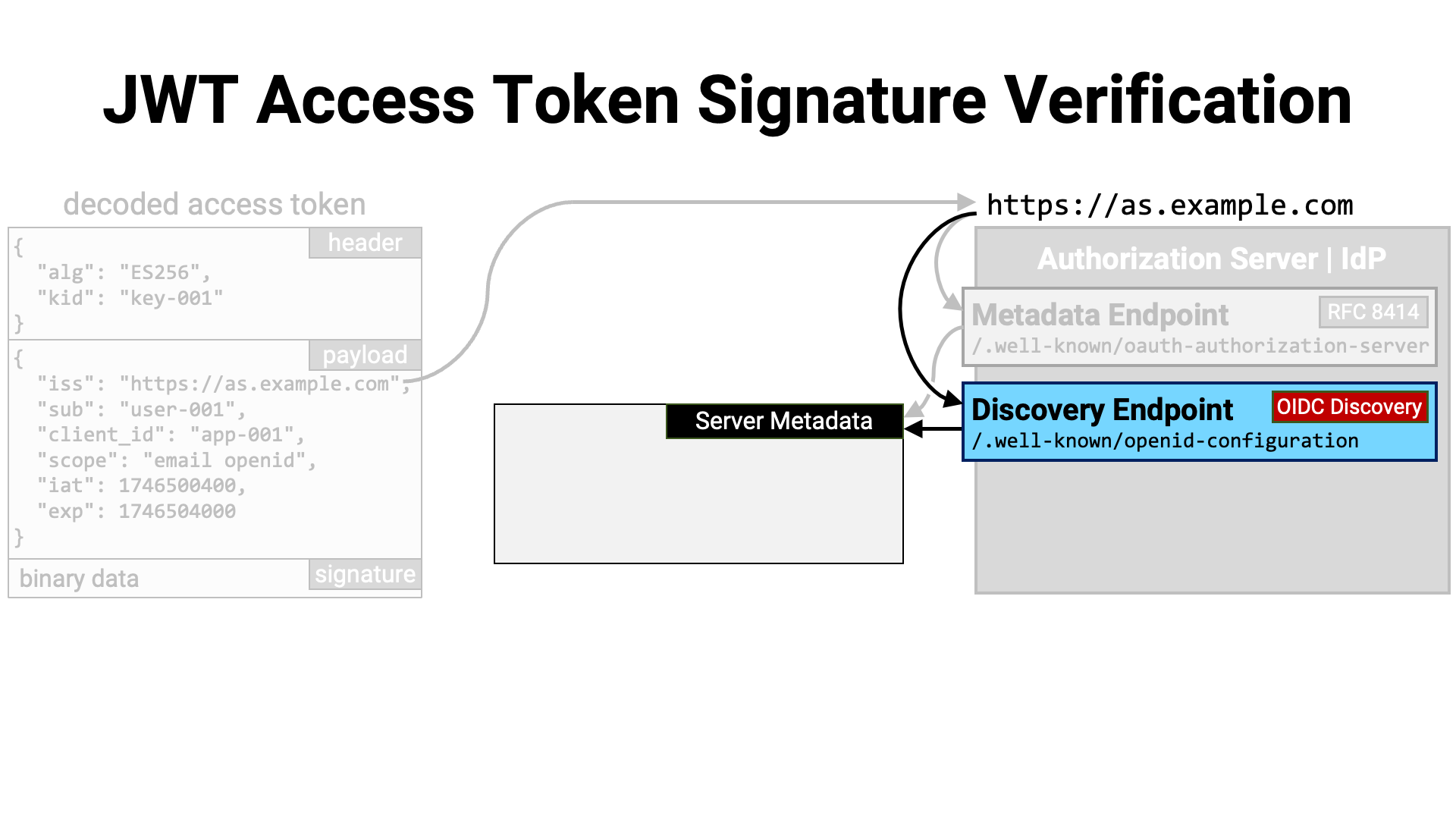
Alternatively, if the server supports
OpenID Connect Discovery 1.0, its metadata is published
at the location obtained by appending
/.well-known/
to the issuer identifier.
Server metadata contains a variety of information, but the most important
field here is the jwks_uri metadata. This field indicates the location
where the server’s JWK Set document is published. The JWK Set document can
be downloaded from this location.
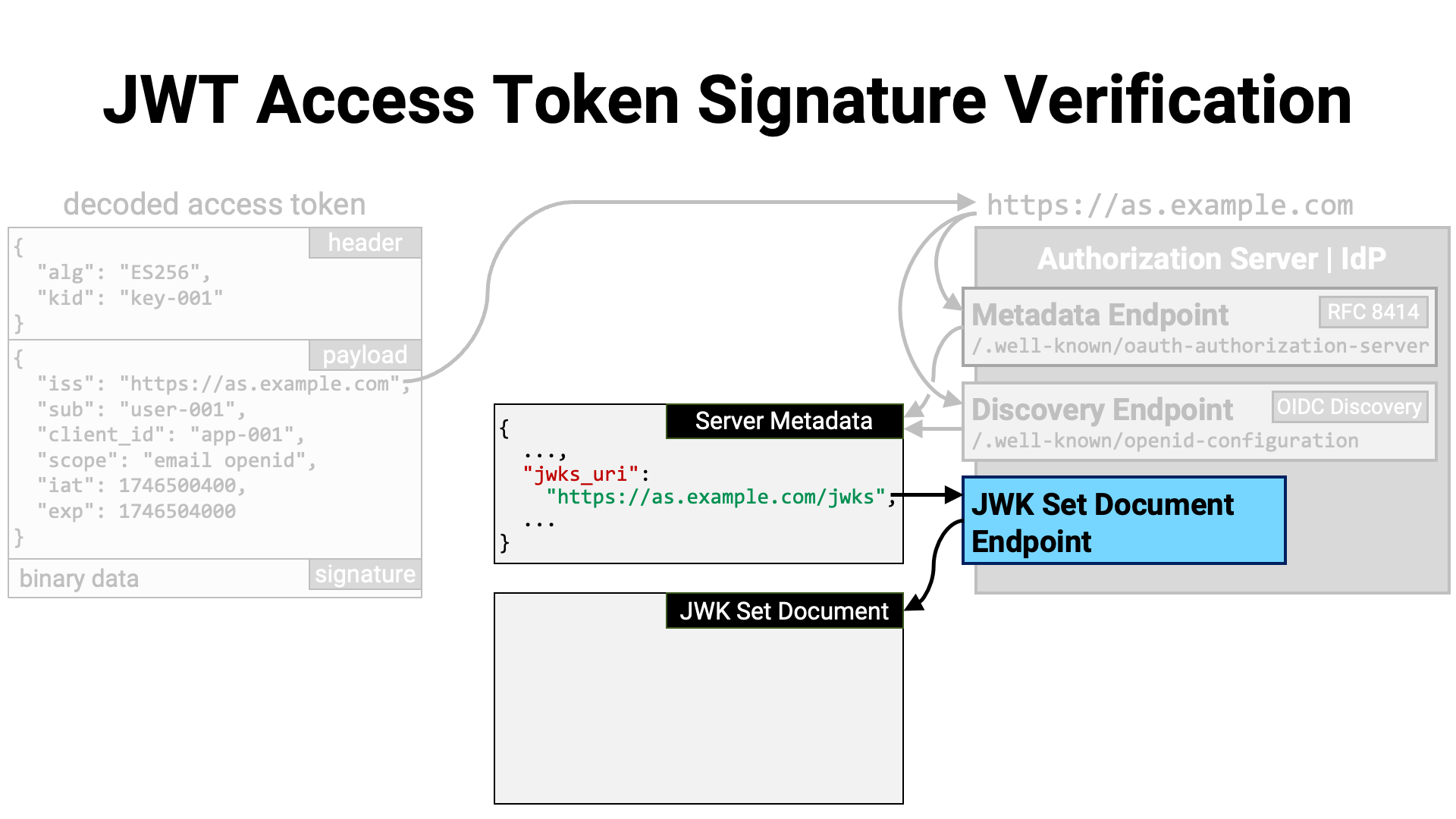
The contents of the JWK Set document follow the format defined in
RFC 7517, Section 5. JWK Set Format. This format is
a JSON object that contains a single top-level property called keys. The
value of the keys property is a JSON array of JWKs (RFC 7517).
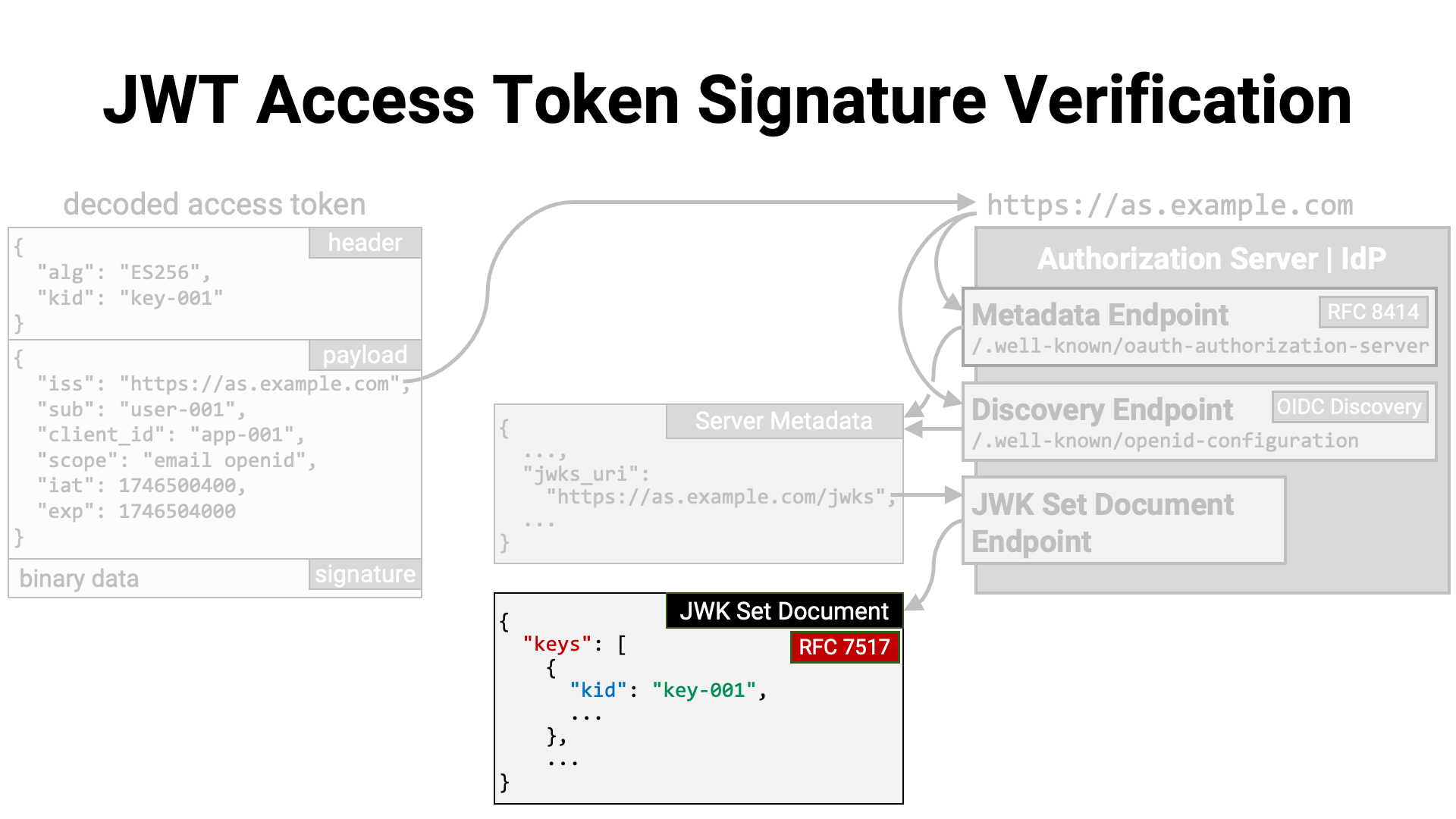
Among the JWKs, there should be a public key for verifying the signature of
the JWT access token. If the JWT’s JWS header includes the kid parameter
(RFC 7515 Section 4.1.4), the verification key can be
identified by looking for a JWK with the same kid
(RFC 7517 Section 4.5).
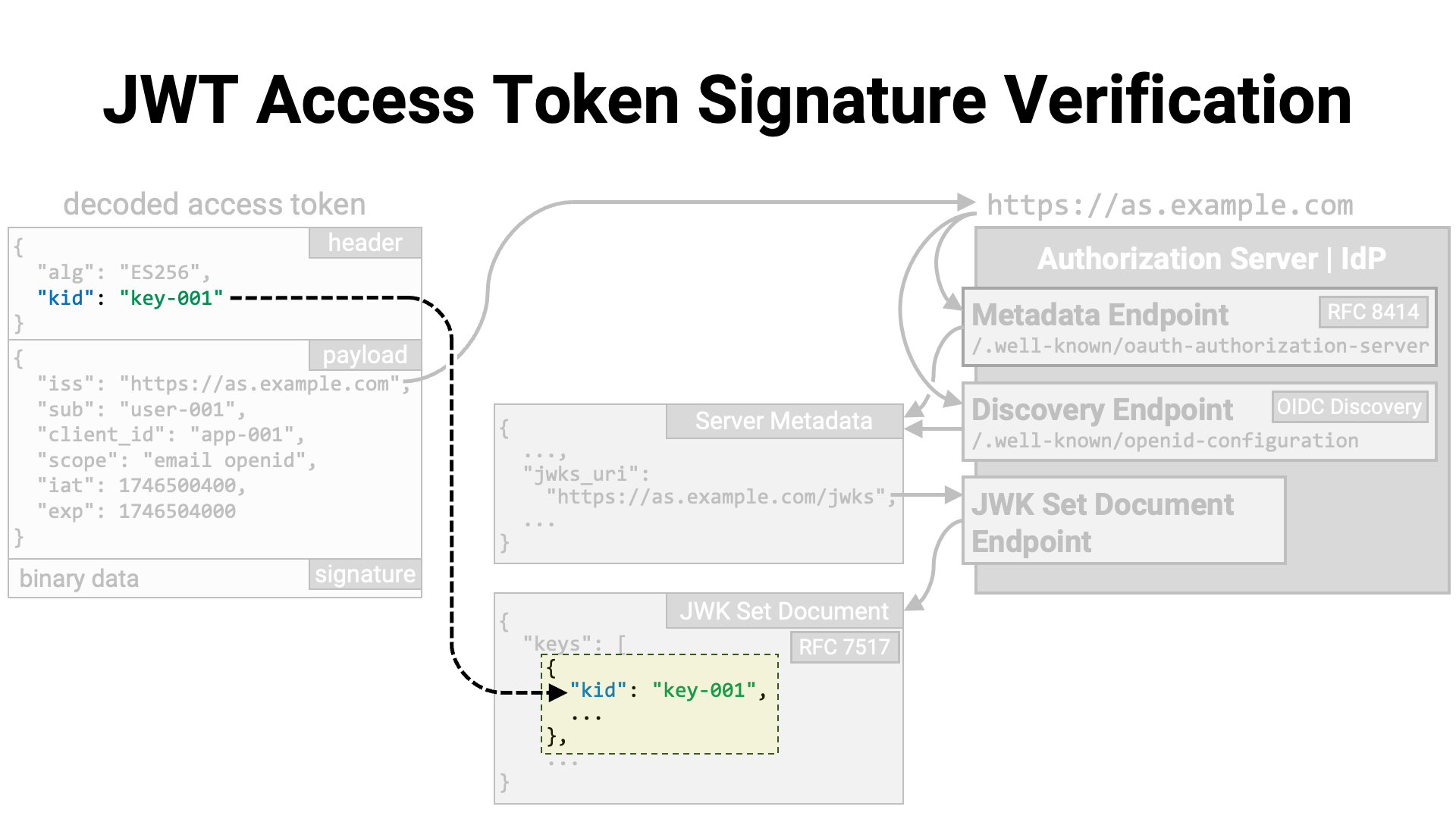
If the JWT does not include a kid, the method for identifying the
verification key will depend on the implementation. For example, the key may
be identified by filtering based on parameters such as alg
(RFC 7515 Section 4.1.1, RFC 7517 Section 4.4)
and use (RFC 7517 Section 4.2).
Once the verification key has been identified, it is used to verify the JWT’s signature. If the verification succeeds, it can be concluded that the JWT access token has not been tampered with.
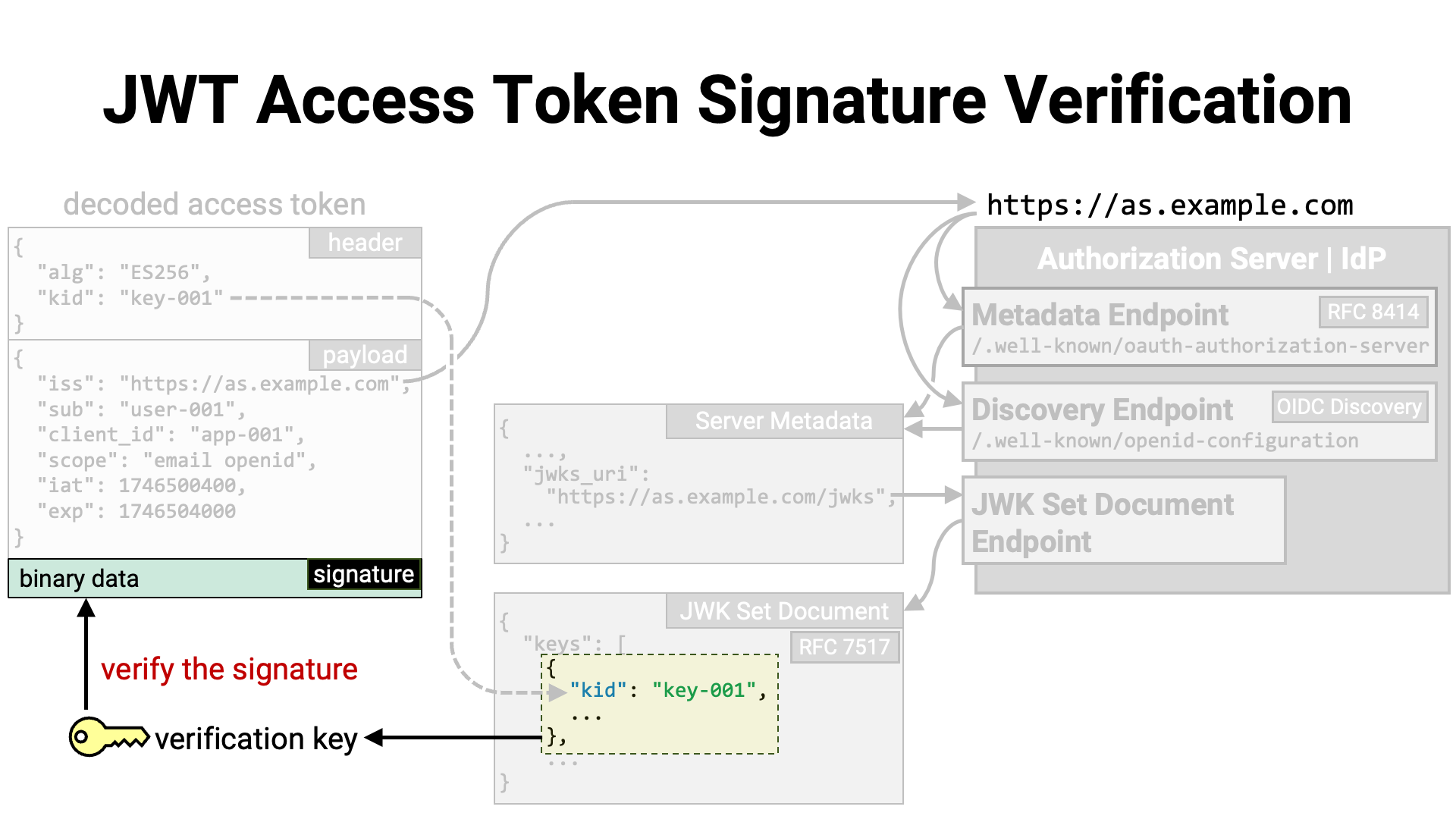
Summary:
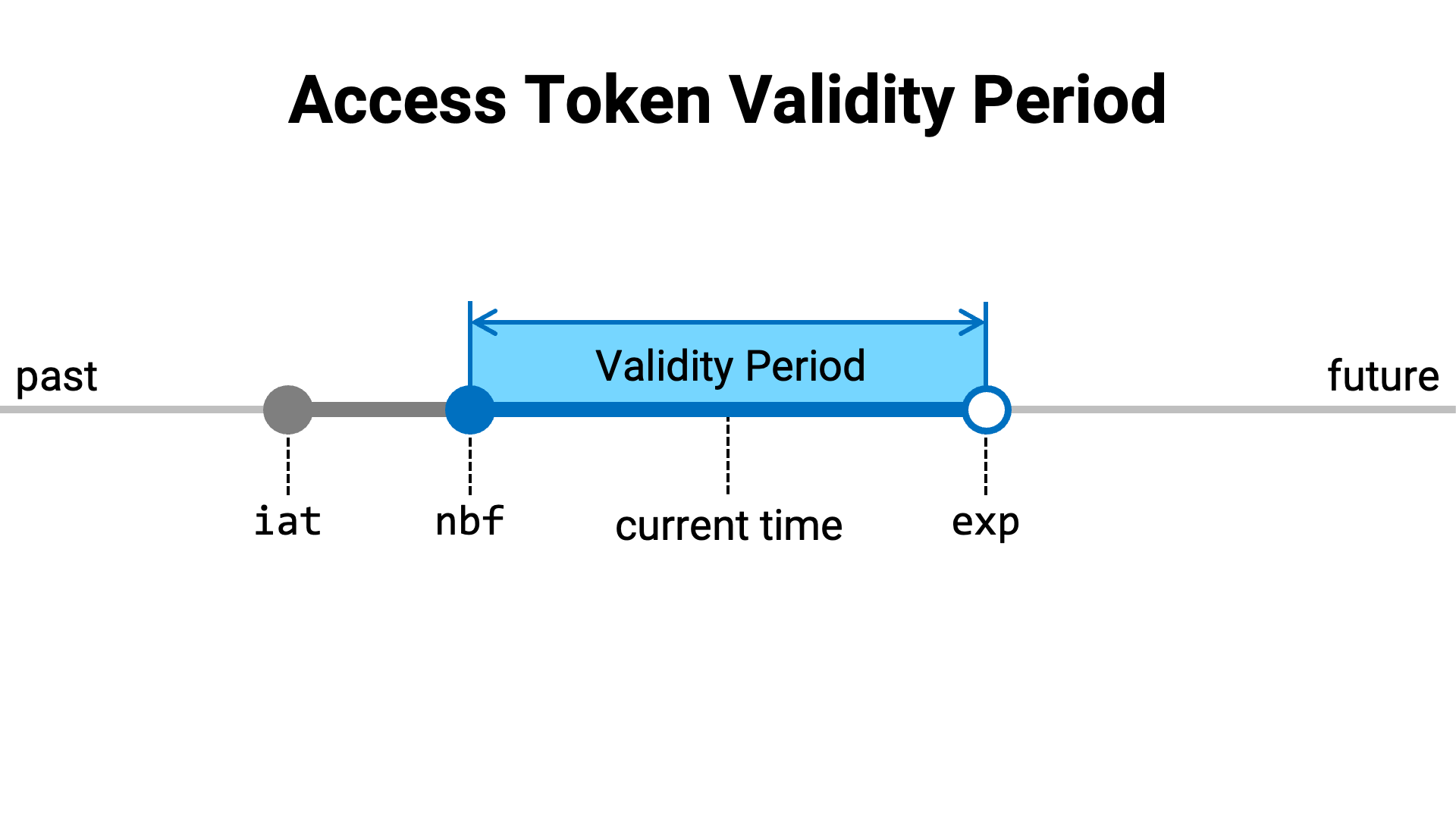
An access token can have up to three time-related attributes:
Regardless of whether the access token information is obtained from an
introspection endpoint or from the payload of a JWT, these values are
referred to by the names iat (Issued At), nbf (Not Before), and exp
(Expiration Time), respectively.
| Name | Introspection Response | JWT Payload | |
|---|---|---|---|
| issuance time | iat |
RFC 7662 Section 2.2 | RFC 7519 Section 4.1.6 |
| validity start time | nbf |
RFC 7662 Section 2.2 | RFC 7519 Section 4.1.5 |
| validity end time | exp |
RFC 7662 Section 2.2 | RFC 7519 Section 4.1.4 |
These attribute values determine the validity period of the access token.
The following diagram illustrates the validity period of an access token
when all three attributes—iat, nbf, and exp—are specified.
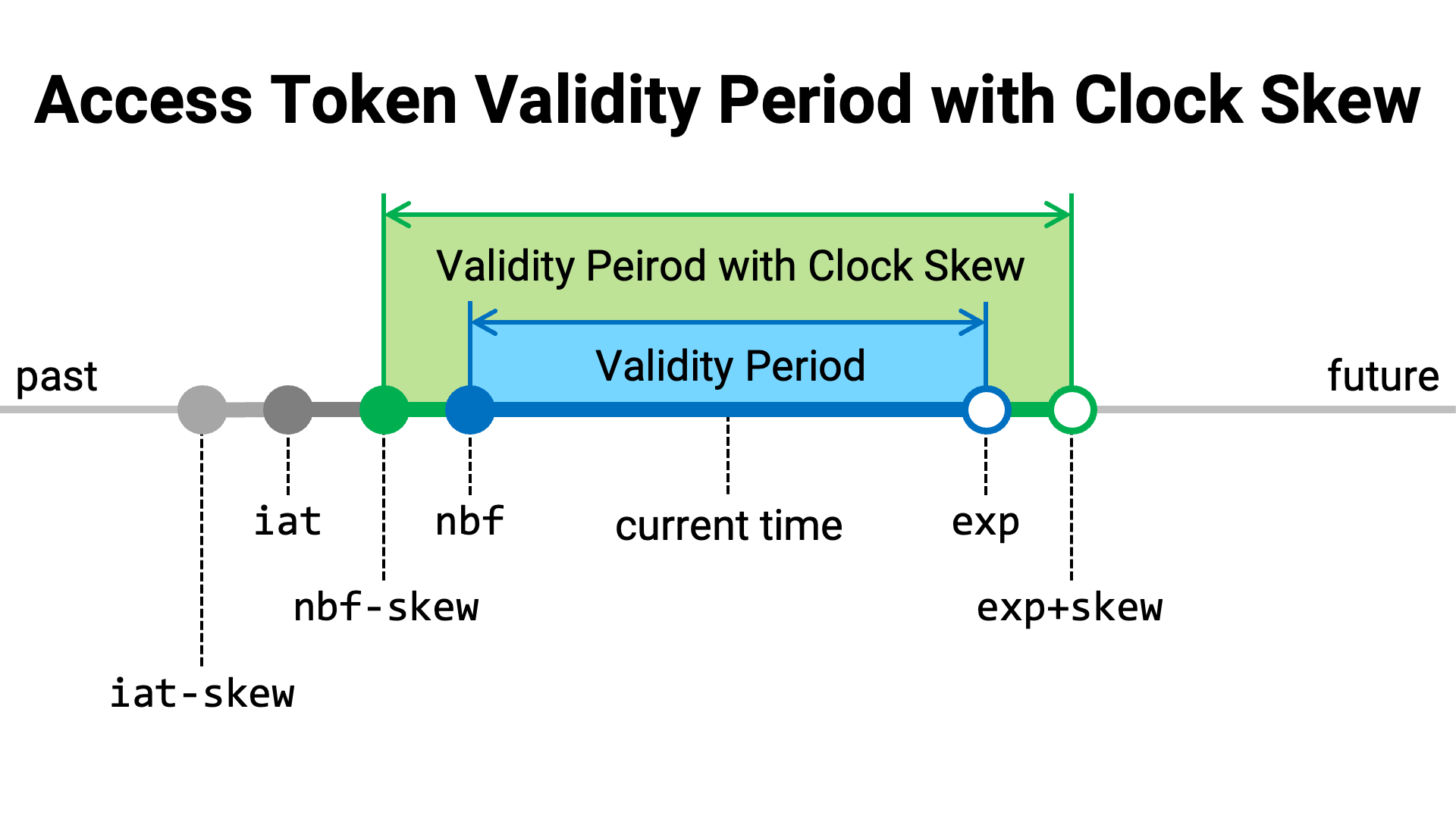
The resource server checks whether the current time falls within the validity period of the access token. Specifically, it performs the following checks:
However, in real-world systems, these checks are performed with clock skew
in mind—i.e., the potential for time discrepancies between systems.
This is because, in practice, valid access tokens are often incorrectly
judged as invalid due to such time differences. For example, if the system
receiving the access token (the resource server) has a clock that lags behind
the system that issued the token (the authorization server), it may mistakenly
determine that the access token’s validity period has not yet started (i.e.,
the current time is earlier than the time specified by nbf).
You may hear opinions such as, “That kind of issue shouldn’t occur if time synchronization is done properly using NTP (Network Time Protocol).” However, in reality, such issues do occur. Insights gained from years of operating open banking ecosystems in various countries are documented in the FAPI 2.0 Security Profile, which we will introduce here.
NOTE 3: Clock skew is a cause of many interoperability issues. Even a few hundred milliseconds of clock skew can cause JWTs to be rejected for being “issued in the future”. The DPoP specification [RFC9449] suggests that JWTs are accepted in the reasonably near future (on the order of seconds or minutes). This document goes further by requiring authorization servers to accept JWTs that have timestamps up to 10 seconds in the future. 10 seconds was chosen as a value that does not affect security while greatly increasing interoperability. Implementers are free to accept JWTs with a timestamp of up to 60 seconds in the future. Some ecosystems have found that the value of 30 seconds is needed to fully eliminate clock skew issues. To prevent implementations switching off
iatandnbfchecks completely this document imposes a maximum timestamp in the future of 60 seconds.
Technically, when accounting for clock skew, there are two approaches: tightening the validation (making tokens less likely to be considered valid), and loosening the validation (making tokens more likely to be considered valid). What is typically required in real-world system operations is the latter.
With this in mind, when comparing iat and nbf to the current time, the
maximum acceptable clock skew (e.g., 10 seconds) should be subtracted from
the iat or nbf value before comparison. Likewise, when comparing exp
to the current time, the clock skew should be added to the exp value
before comparison.
One of the fundamental attributes of an access token defined in RFC 6749 is the scope (RFC 6749 Section 3.3). The scope represents the set of permissions granted to the access token.
API sets may require that an access token possess specific scopes, depending on their respective purposes. Which scopes are required is entirely up to the API provider to define. Before proceeding with any processing, the API implementation checks whether the presented access token includes the required scopes.
A client application must first determine which scopes are required by the APIs
it intends to use, and then include those scopes as part of its request when
asking the authorization server to issue an access token. Specifically, for
example, when using the authorization code flow
(RFC 6749 Section 4.1) to request the issuance of an access
token, the client lists the individual scope names, separated by spaces, as the
value of the scope request parameter in the authorization request
(RFC 6749 Section 4.1.1).
Let’s look at a concrete example.
Suppose a client application wants to use the GET /ssf/status API and the
POST /ssf/status API provided by a certain server. Assume that the
GET /ssf/status API requires the ssf:
scope, and the POST /ssf/status API requires the
ssf: scope.
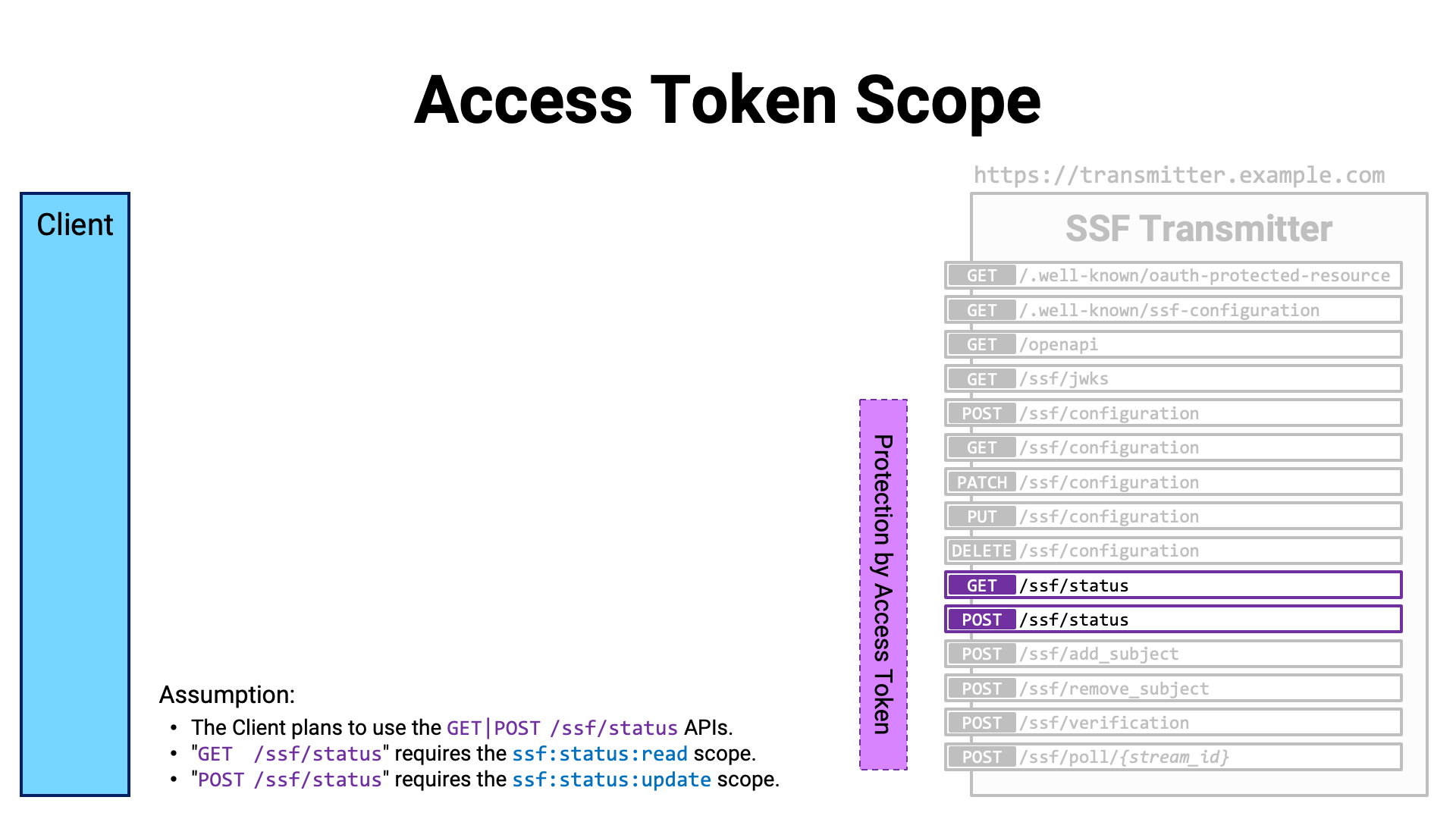
The client application sends an authorization request to the authorization
server, including those scope names in the value of the scope request
parameter.
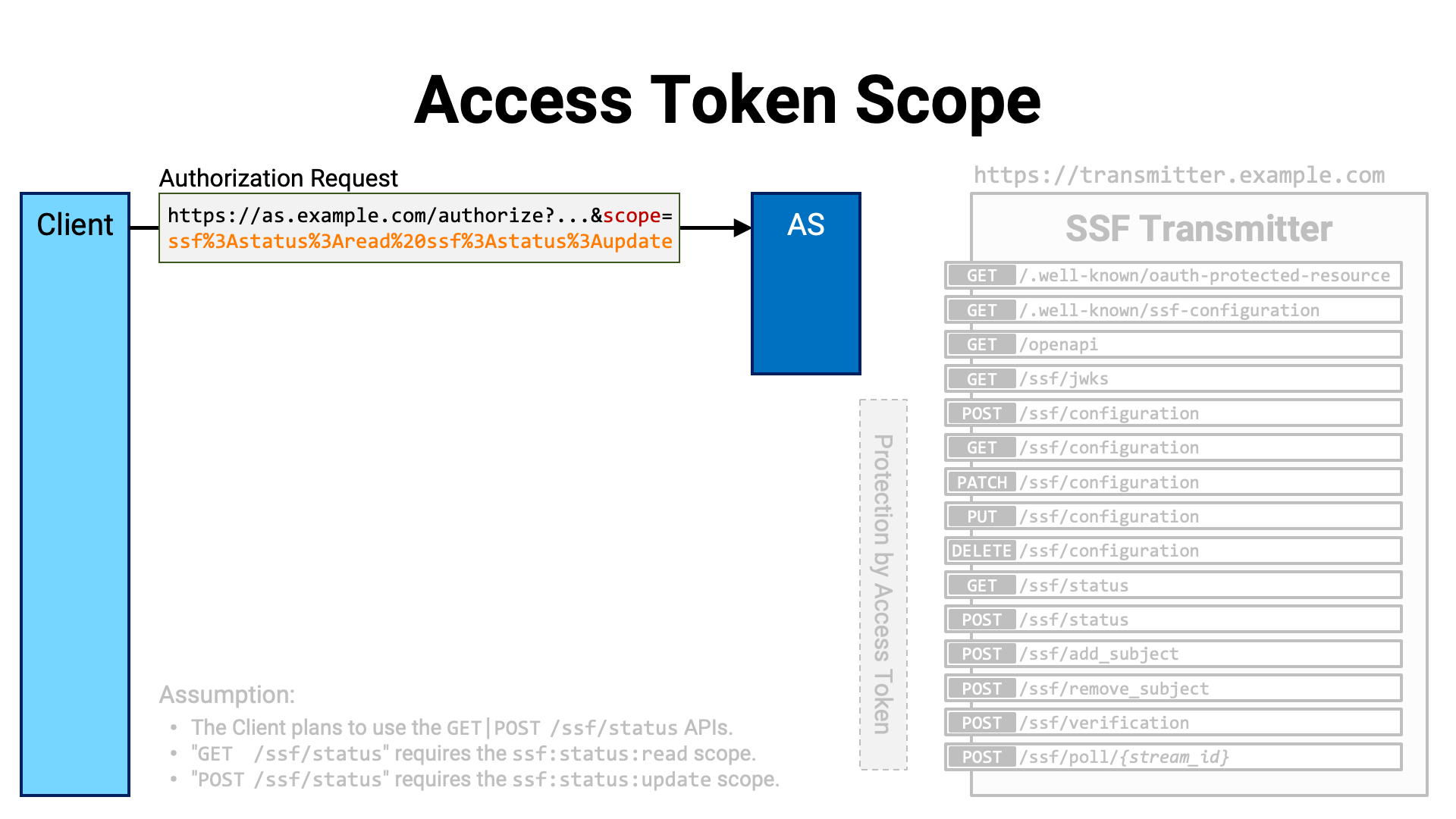
After obtaining the user’s consent, the authorization server issues an access token to the client application with the requested scopes attached.
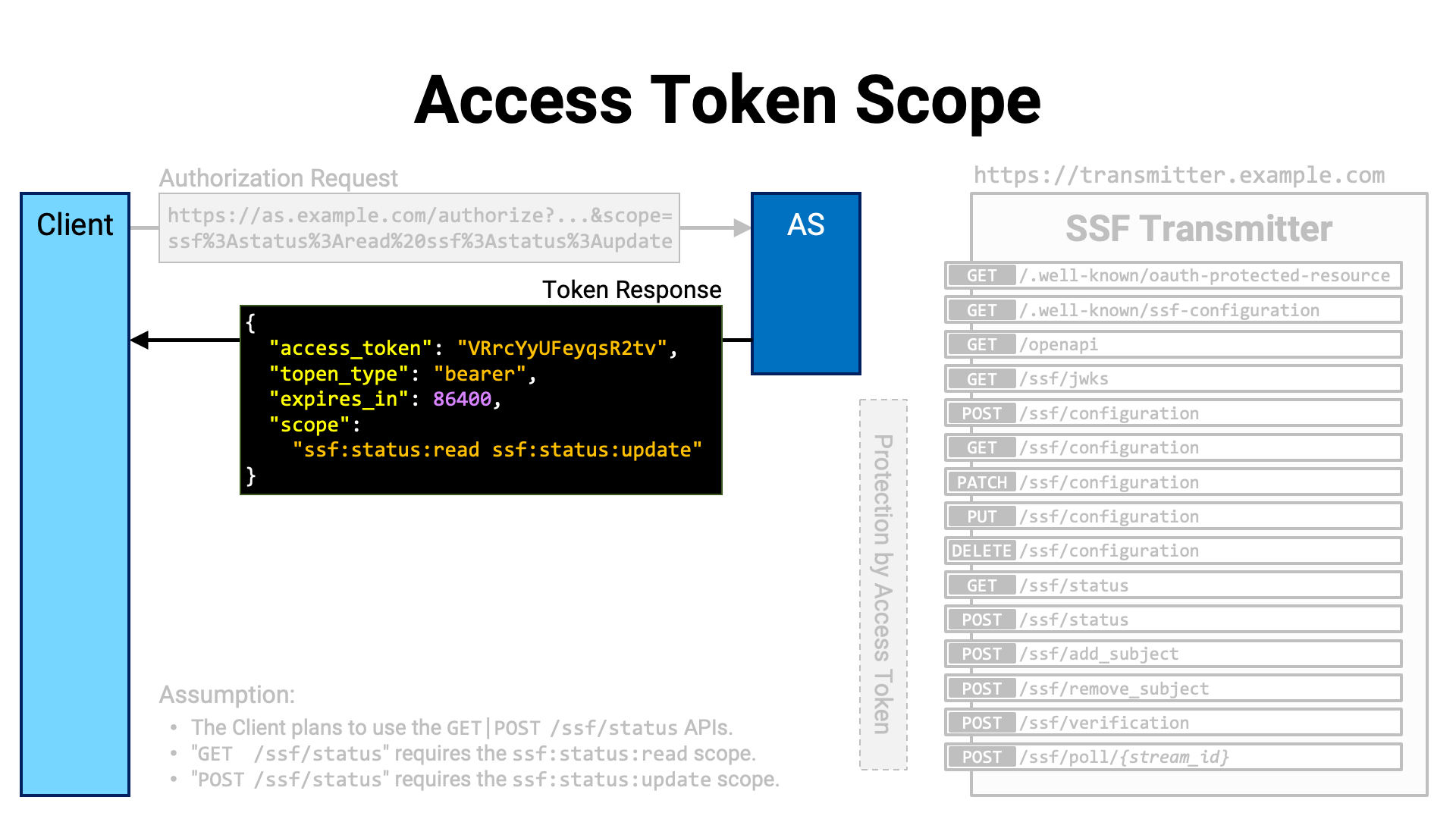
The client application accesses the API with the access token attached.

Summary:

There is a method to restrict the audience of an access token.
By using this method, for example, it is possible to designate only a specific resource server as the audience, or to specify only a group of endpoints under a certain path hierarchy as the intended audience. This helps reduce the risk of misuse or abuse of the access token.
The audience of an access token is represented by the aud parameter, both in
introspection responses (RFC 7662) and in JWT access tokens.
| Name | Introspection Response | JWT Payload | |
|---|---|---|---|
| audience | aud |
RFC 7662 Section 2.2 | RFC 7519 Section 4.1.3 |
For example, if an introspection response includes https://rs.example.com in
the value of its aud property, it means that the access token can be used
only at https://rs.example.com.
{
"aud": [
"https://rs.example.com"
]
}
If that access token is presented to
https://, and if the APIs on
https:// are correctly validating
the aud property of the access token, the token will be rejected.
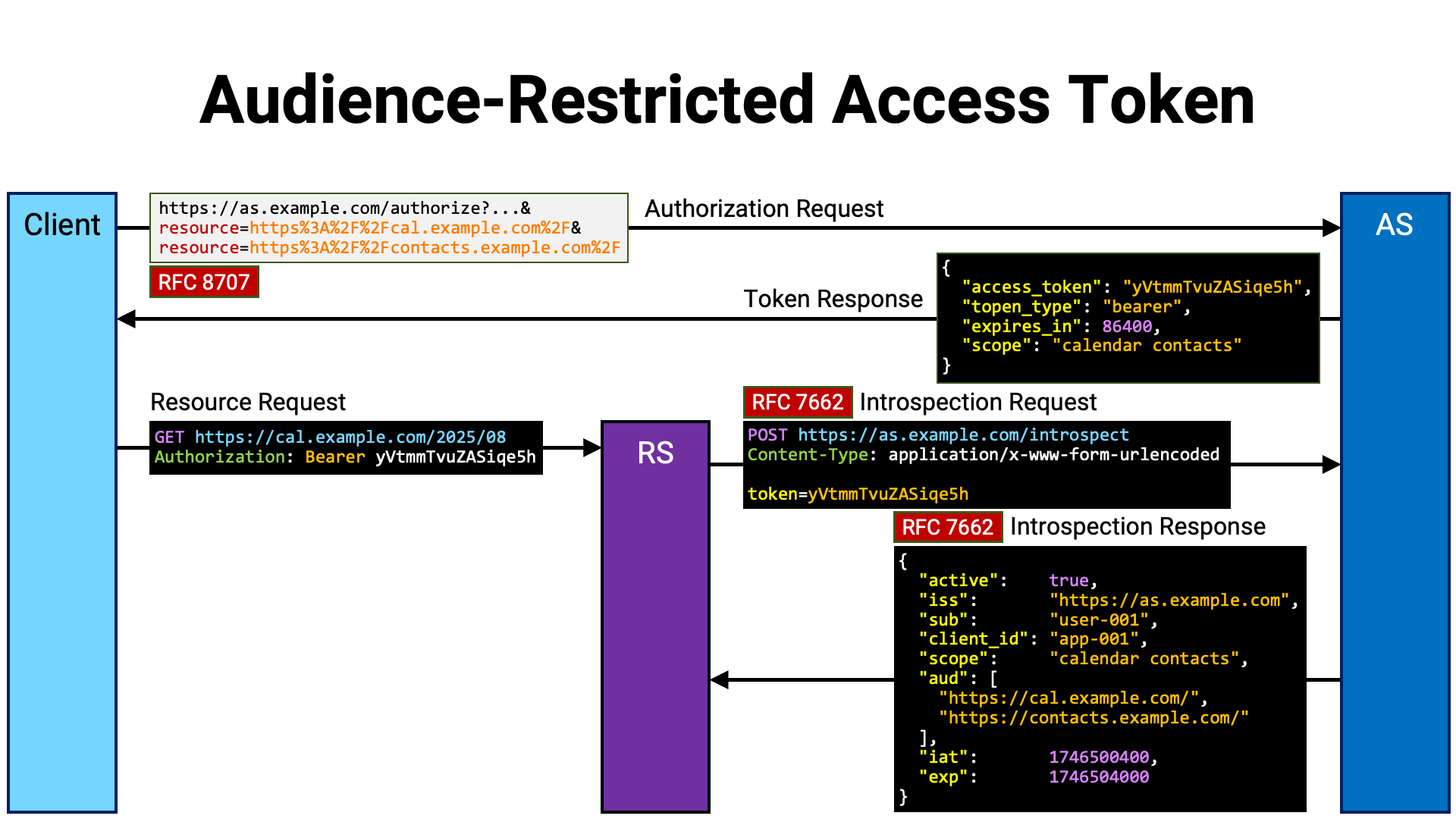
Restricting the audience of an access token is done using the resource
request parameter defined in Section 2 of RFC 8707
(Resource Indicators for OAuth 2.0).
When a resource request parameter is included in an authorization or token
request, its value is set as the audience of the access token. Below is an
example of how to use the resource parameter, excerpted from
Section 2.1 of RFC 8707. In this example,
https:// and
https:// are specified as
the intended audiences of the access token.
GET /as/authorization.oauth2?response_type=code
&client_id=s6BhdRkqt3
&state=tNwzQ87pC6llebpmac_IDeeq-mCR2wLDYljHUZUAWuI
&redirect_uri=https%3A%2F%2Fclient.example.org%2Fcb
&scope=calendar%20contacts
&resource=https%3A%2F%2Fcal.example.com%2F
&resource=https%3A%2F%2Fcontacts.example.com%2F HTTP/1.1
Host: authorization-server.example.com
RFC 8707 refers to access tokens with restricted recipients as “audience-restricted” access tokens.
Traditional access tokens, if leaked, can be used by unauthorized parties to access protected APIs. This is similar to a situation in which a lost train ticket can be picked up and used by someone else to board the train.
One way to mitigate this vulnerability is to verify, at the time of API access, that the entity using the access token is the same as the entity to which the token was originally issued. This is analogous to the check performed when boarding an international flight, where passengers are required to present both a ticket and a passport to ensure that the ticket holder is indeed the rightful user.
The proof that shows the presenter is the legitimate holder of the access token is referred to as Proof of Possession (PoP). By requiring client applications to present a PoP along with the access token, resource servers can ensure that merely possessing the token is not sufficient to gain access, thereby preventing unauthorized use even if the token is stolen.
By requiring PoP, the sender of the access token is effectively constrained. For this reason, access tokens that must be accompanied by PoP at the time of use are referred to as “sender-constrained” access tokens.
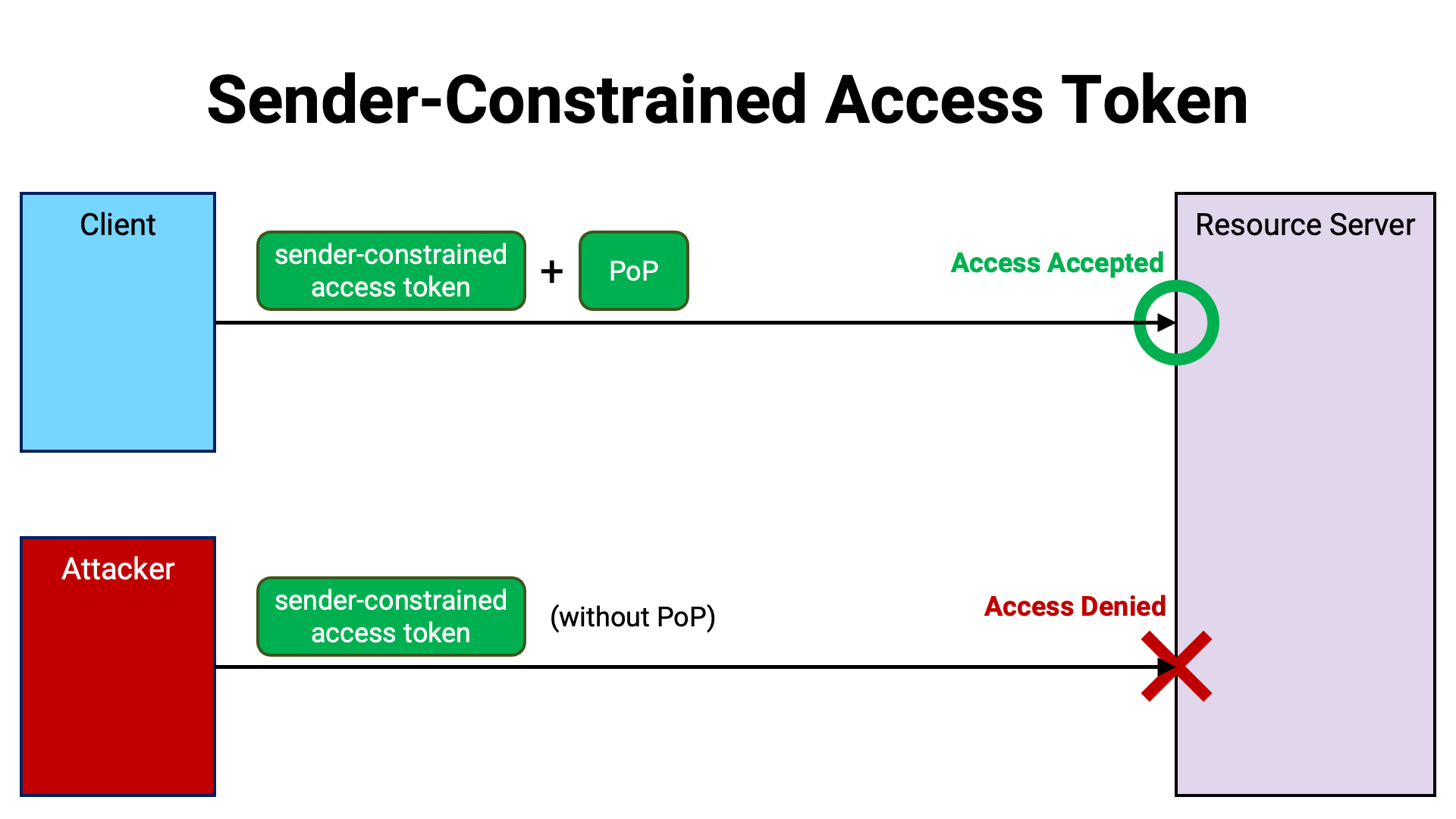
There are two methods for implementing sender-constrained access tokens: MTLS (RFC 8705 Section 3) and DPoP (RFC 9449). The following two sections describe these methods.
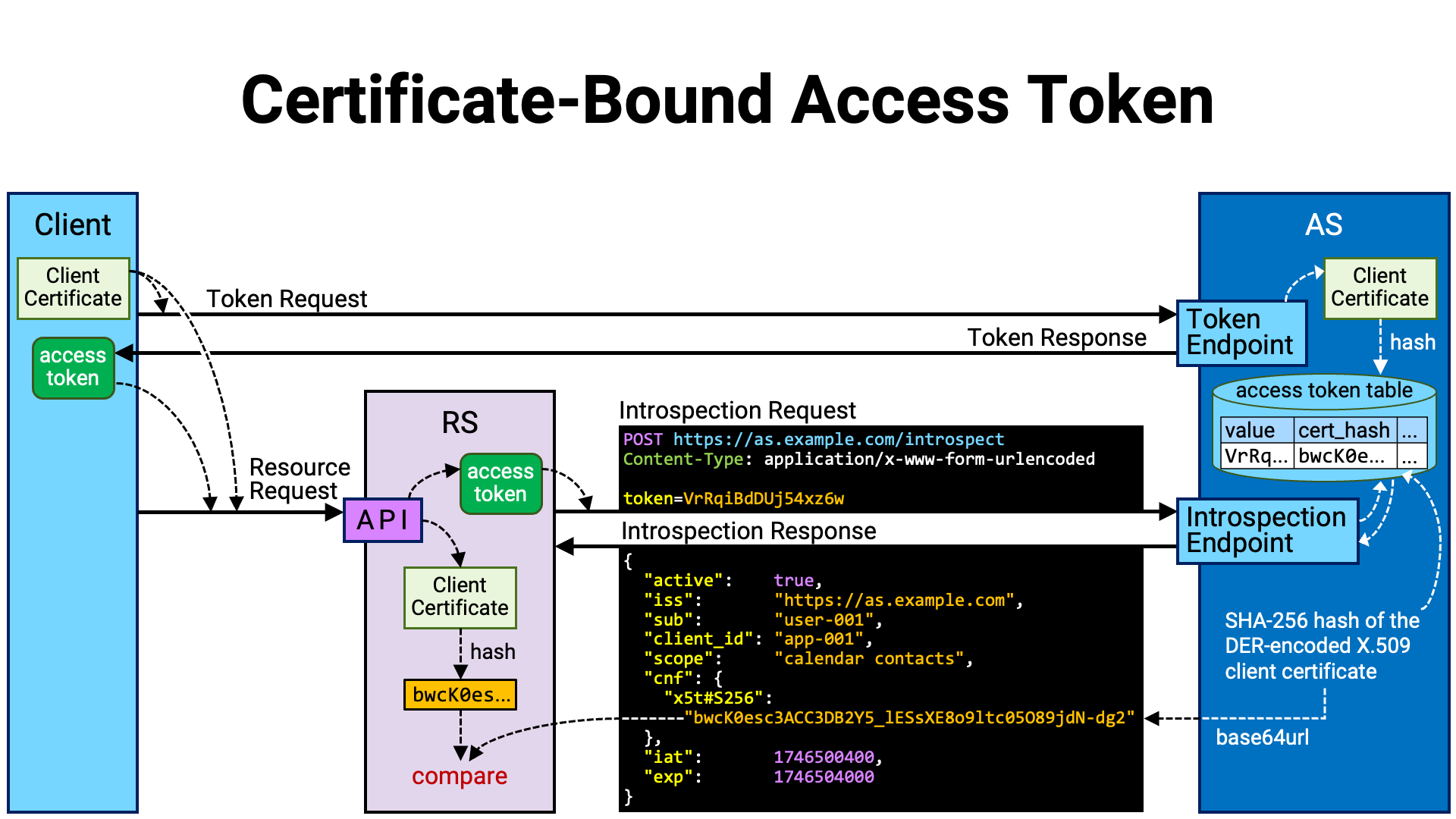
RFC 8705 Section 3 defines a method (hereafter referred to as MTLS) for implementing PoP using an X.509 certificate (RFC 5280) of the client application (hereafter referred to as the client certificate).
When using MTLS, it is a prerequisite that the TLS connection between the client application and the authorization server’s token endpoint, as well as the TLS connection between the client application and the resource server’s API, are mutual TLS connections. In addition, the client application is required to present the same certificate in both of these TLS connections.
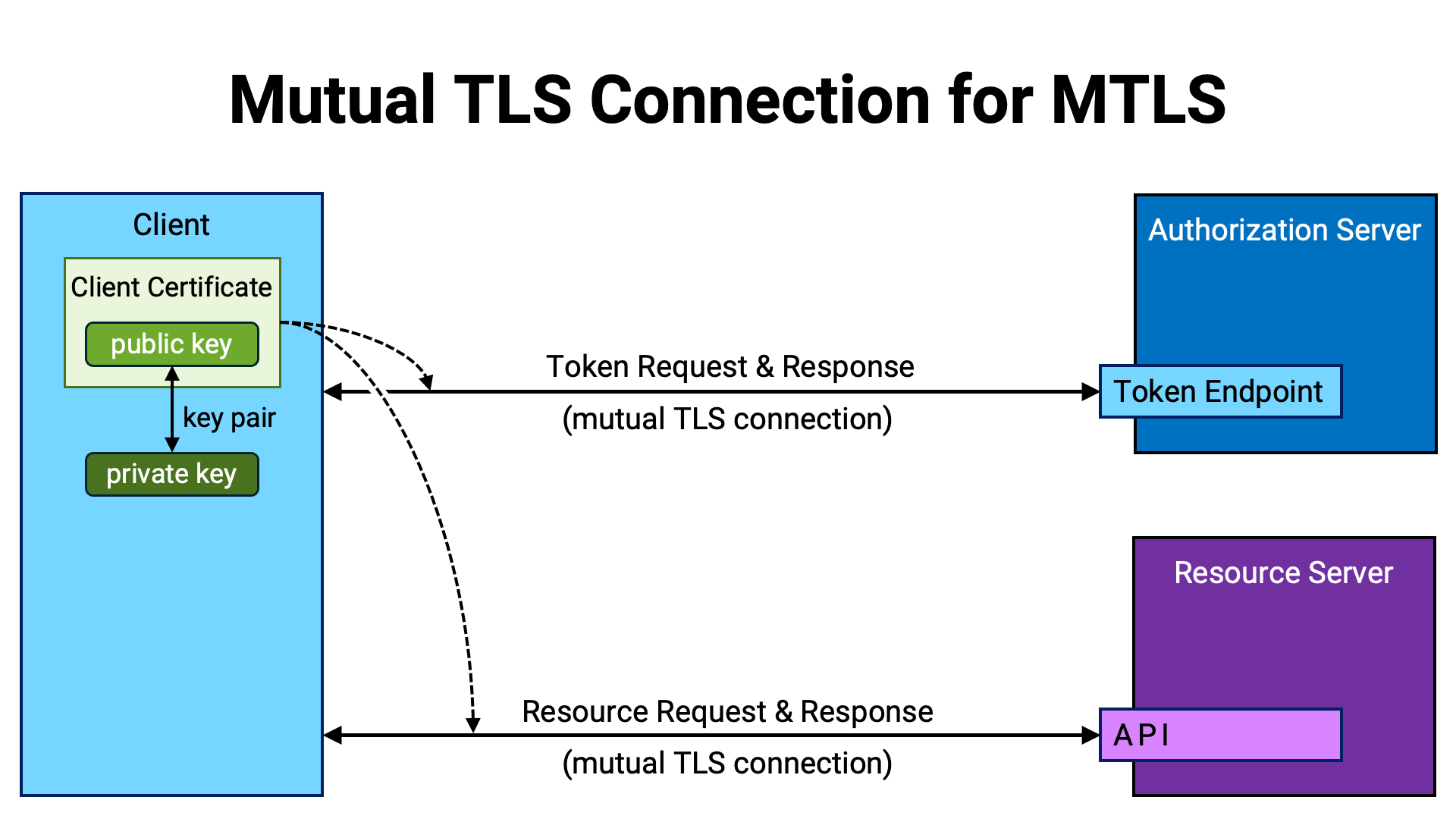
A mutual TLS connection is a TLS connection in which both parties (the client and the server) authenticate each other’s legitimacy. In a standard TLS connection, the server presents its own certificate, and the client verifies that certificate. In contrast, in a mutual TLS connection, the client also presents its own certificate, and the server verifies the client’s certificate as well.
The basic idea behind MTLS is to associate the access token with “the client certificate used in the mutual TLS connection of the token request” and remember it. Later, during a resource request, the server checks whether “the client certificate used in the mutual TLS connection of the resource request” is the same as the one associated with the access token included in the request.
If they match, the client application making the resource request is considered to be the same as the one that made the token request. If they do not match, the client application making the resource request is deemed not to be the legitimate holder of the access token, and the resource request is rejected.
Now, let’s walk through the procedure by which a sender-constrained access token is achieved using MTLS.
The client application establishes a mutual TLS connection with the authorization server’s token endpoint and sends a token request. Since it is a mutual TLS connection, the client presents its client certificate to the server.

In the token endpoint implementation, if the token request is valid, the authorization server generates an access token and stores it in the database. However, if the access token is in a format that embeds the necessary information within itself (such as a JWT access token), it is also possible to implement it without writing data to the database.

At this point, the authorization server extracts the client certificate from the mutual TLS connection, calculates its hash value, and associates it with the access token. Here, the hash value is the SHA-256 hash (NIST FIPS 180-4) of the DER-encoded (X.690) client certificate.
An access token that is associated with a certificate in this way is called a “certificate-bound” access token.

The token endpoint returns a token response containing the generated access token to the client application.

After obtaining the access token, the client application establishes a mutual TLS connection with the resource server’s API, using the same client certificate that was used for the token request.
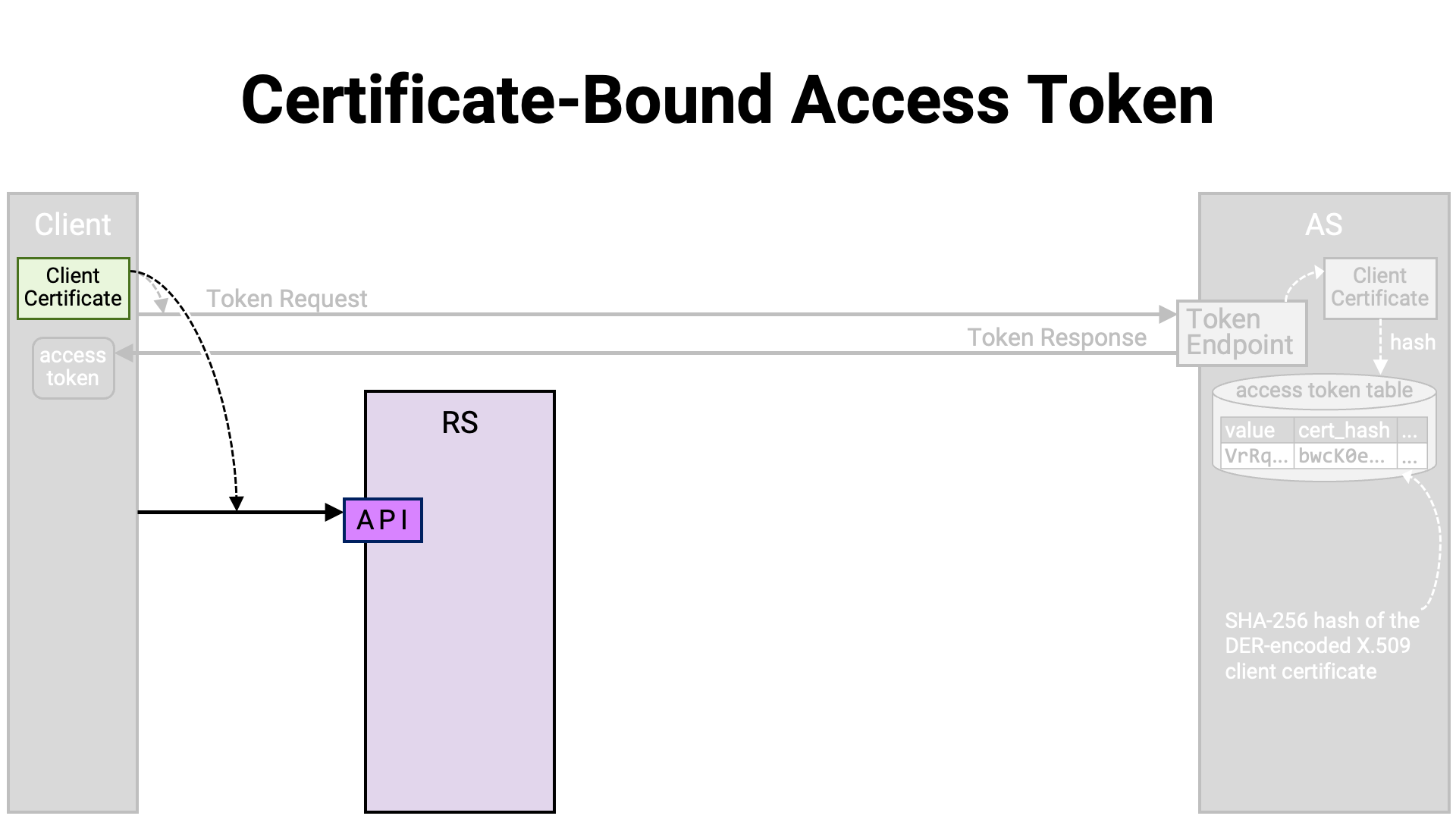
After the connection is established, the client application sends the resource request along with the access token.
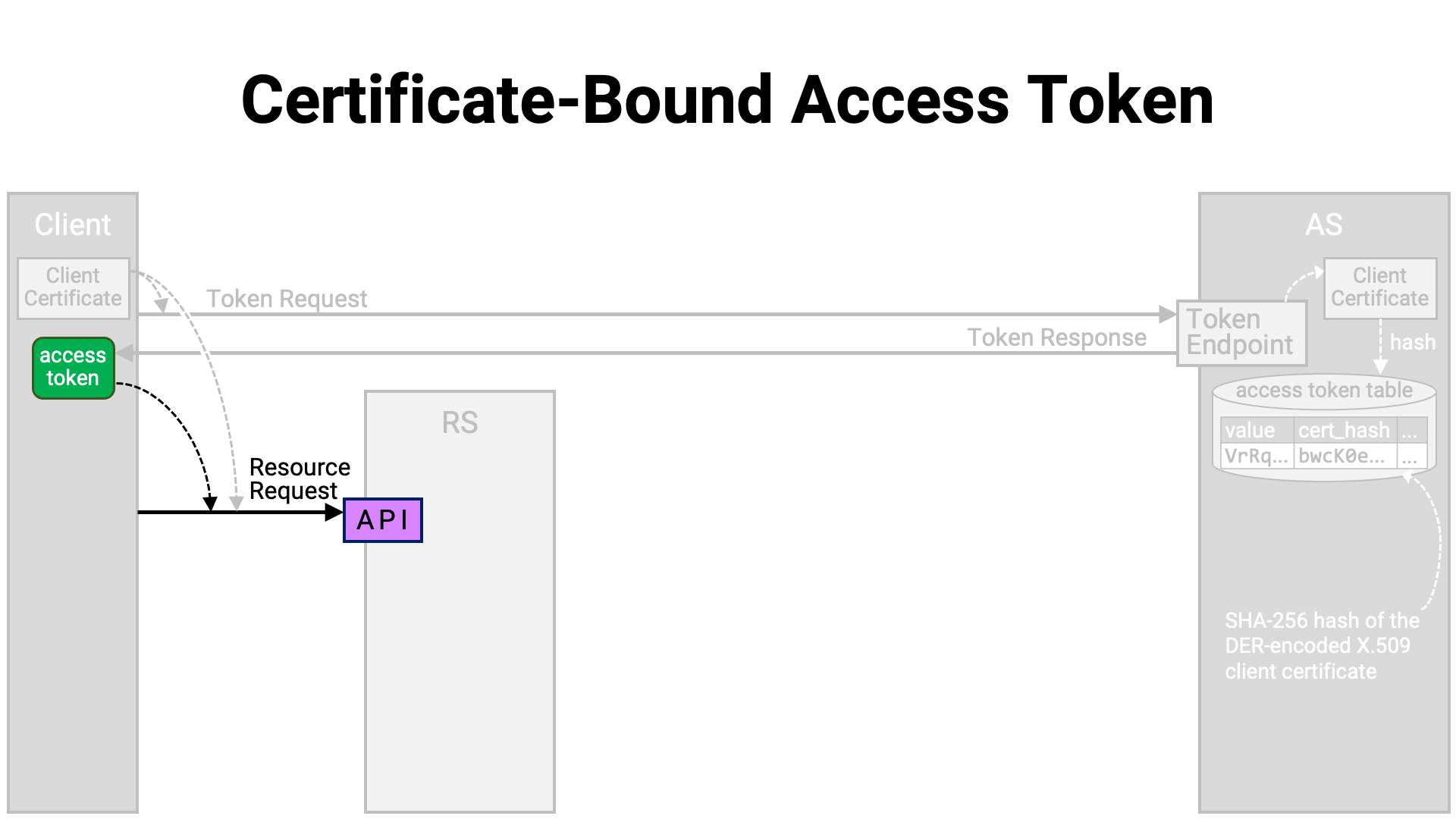
The API implementation extracts the access token from the request and sends it to the authorization server’s introspection endpoint for obtaining information about it. However, if the access token contains its own information, the implementation reads the contents of the access token instead of querying the introspection endpoint.
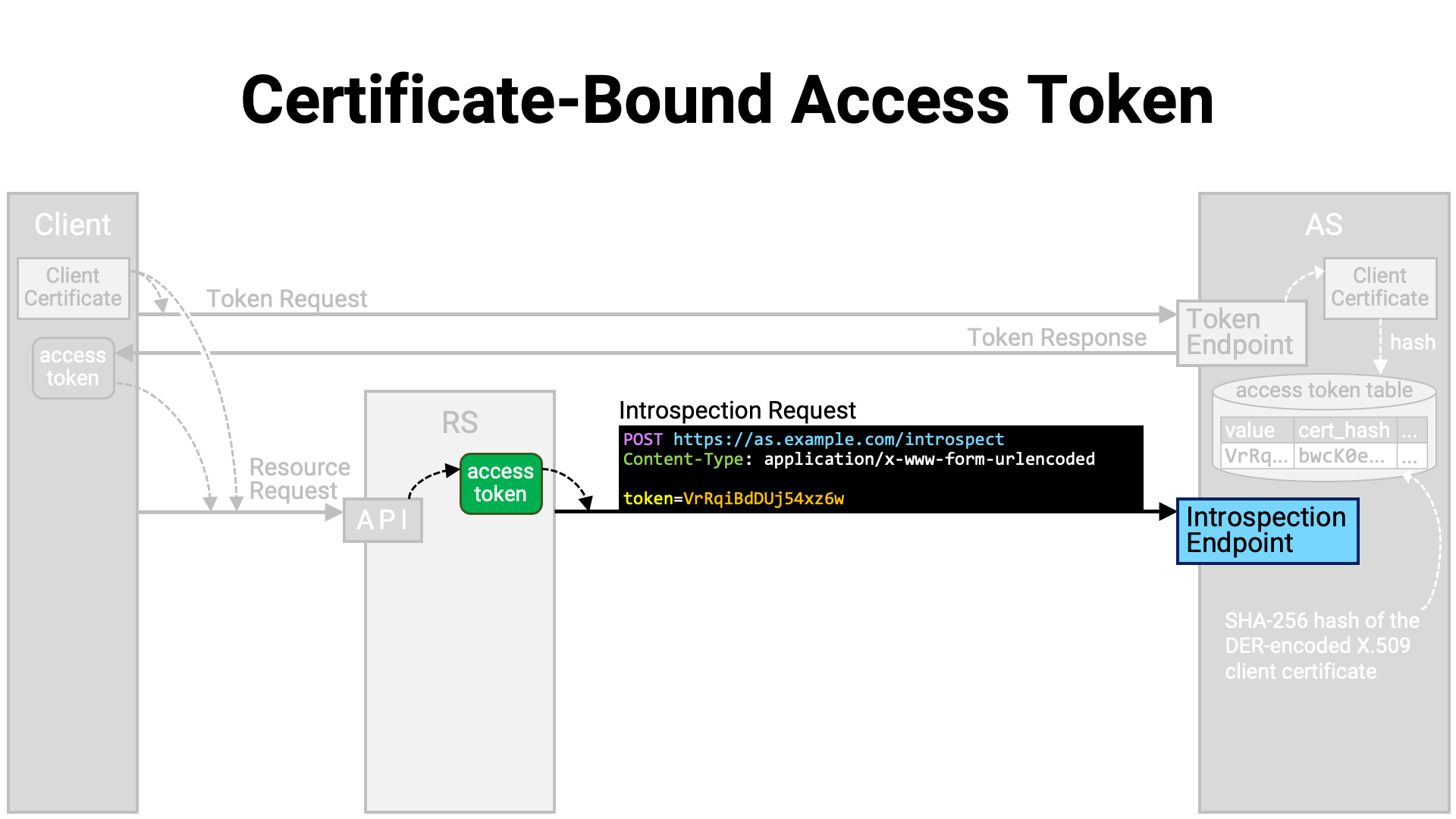
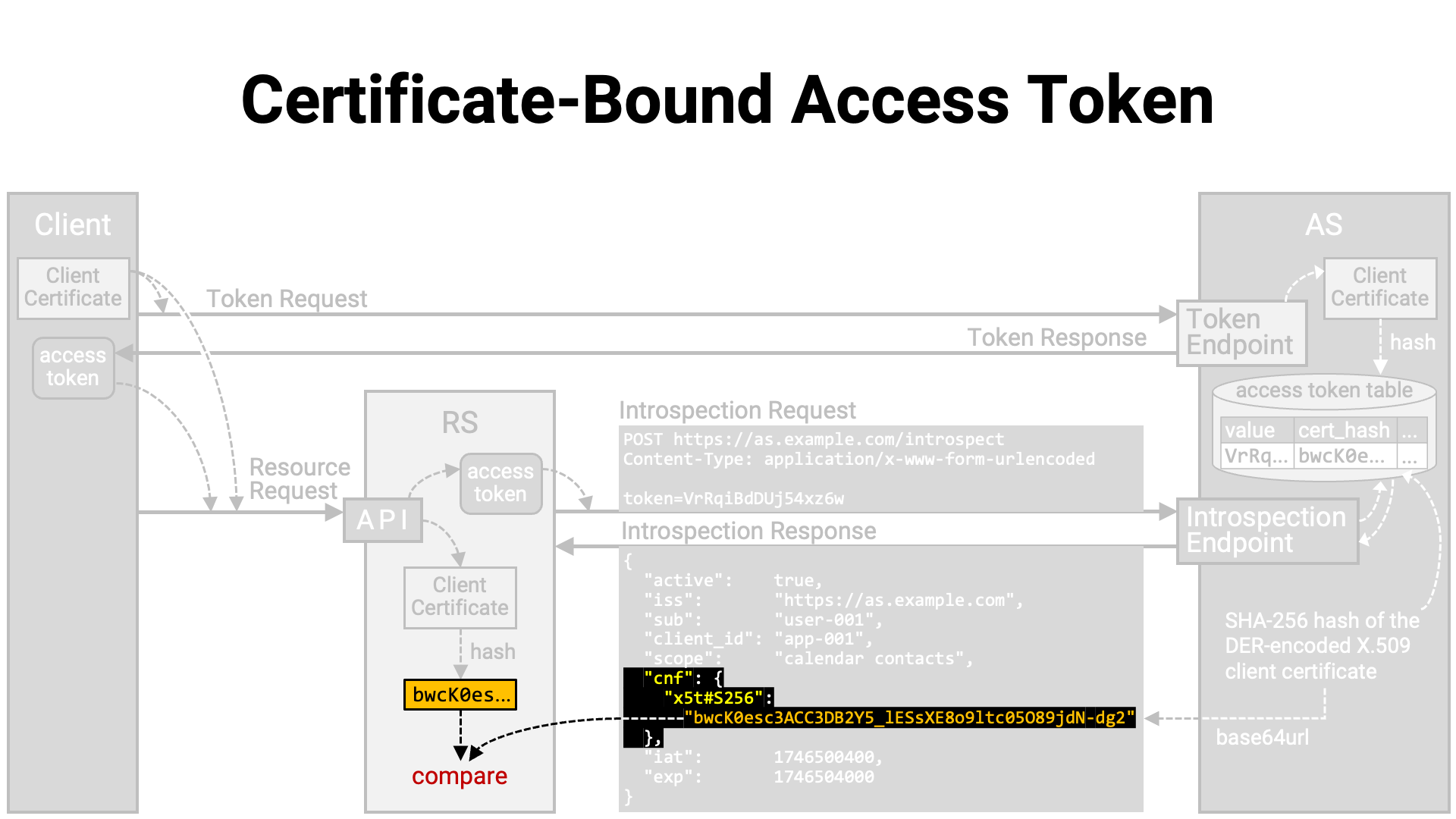
The introspection endpoint implementation retrieves the information of the
presented access token from the database, formats it into an introspection
response, and returns it to the resource server. At this time, the hash value
of the client certificate associated with the access token is base64url-encoded
(RFC 4648) and embedded in the introspection response as the value
of the x5t#S256 sub-property within the top-level cnf property.

Next, the API implementation extracts the client certificate from the mutual TLS connection with the client application and computes its hash value.
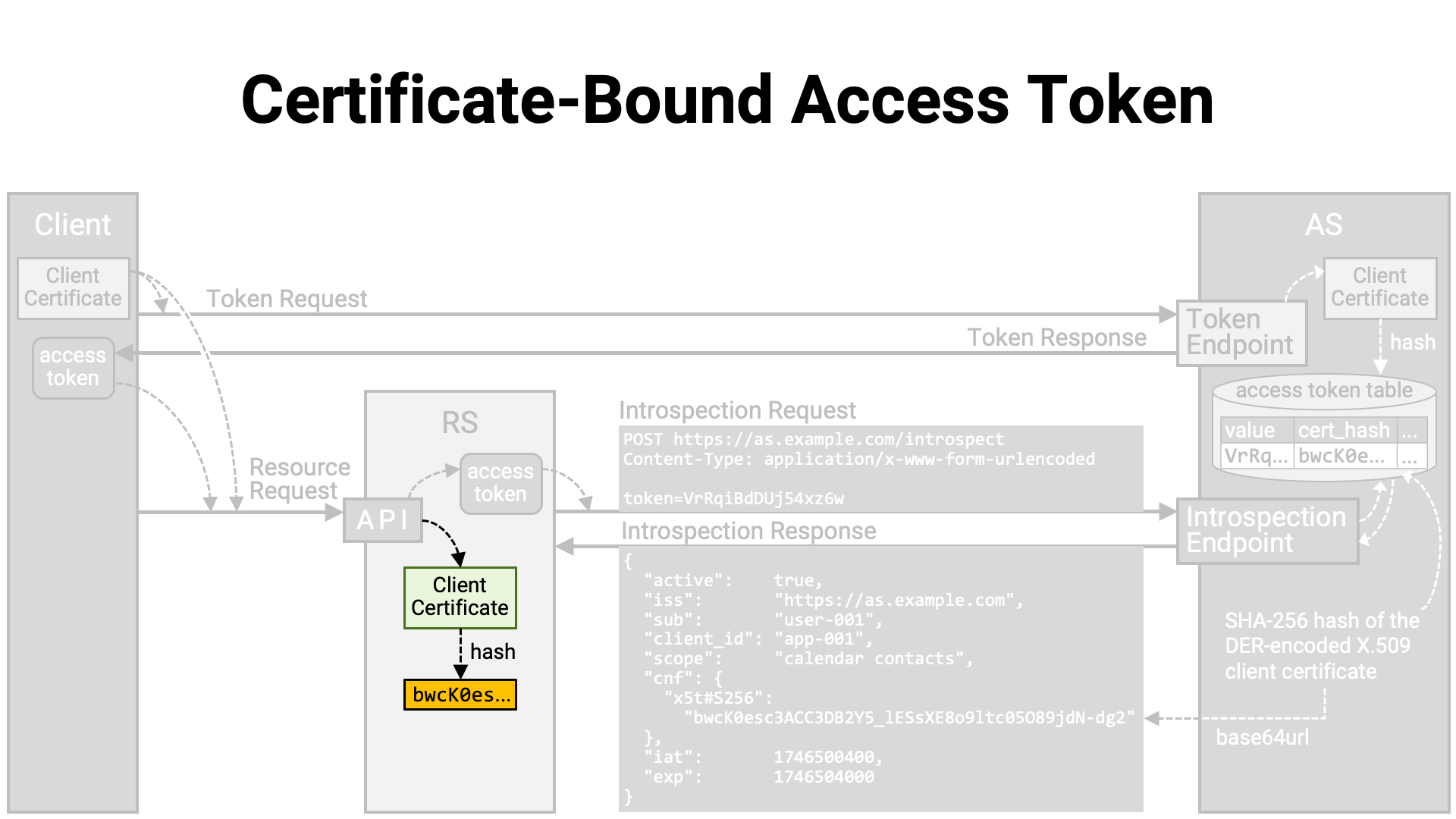
Then, it verifies whether the computed hash value matches the hash value included in the introspection response. If they do not match, the client application making the resource request is considered not to be the legitimate holder of the access token, and the resource request is denied.
Summary:
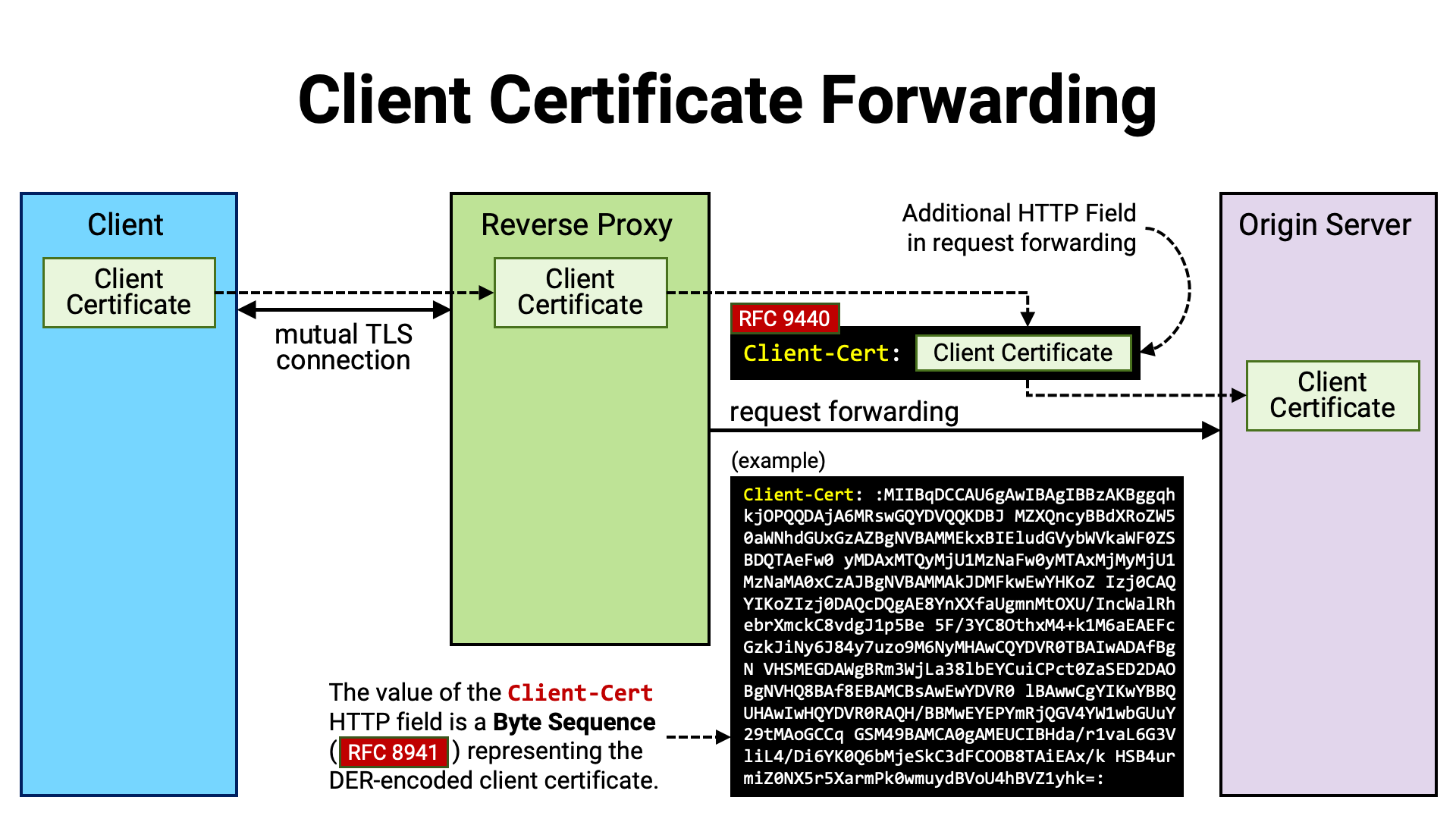
When deploying a TLS-protected application server, it is common to place a reverse proxy between the client and the application server. The reverse proxy handles the TLS connection with the client, terminates it there, and then forwards the client’s requests to the application server sitting behind it.
In such a setup, the application server does not establish a TLS connection directly with the client. Therefore, even if the client establishes a mutual TLS connection with the reverse proxy, the application server cannot access the client certificate presented during that connection. If the application server’s logic needs to refer to the client certificate (for example, to generate or validate a certificate-bound access token), the certificate must somehow be forwarded from the reverse proxy to the application server.
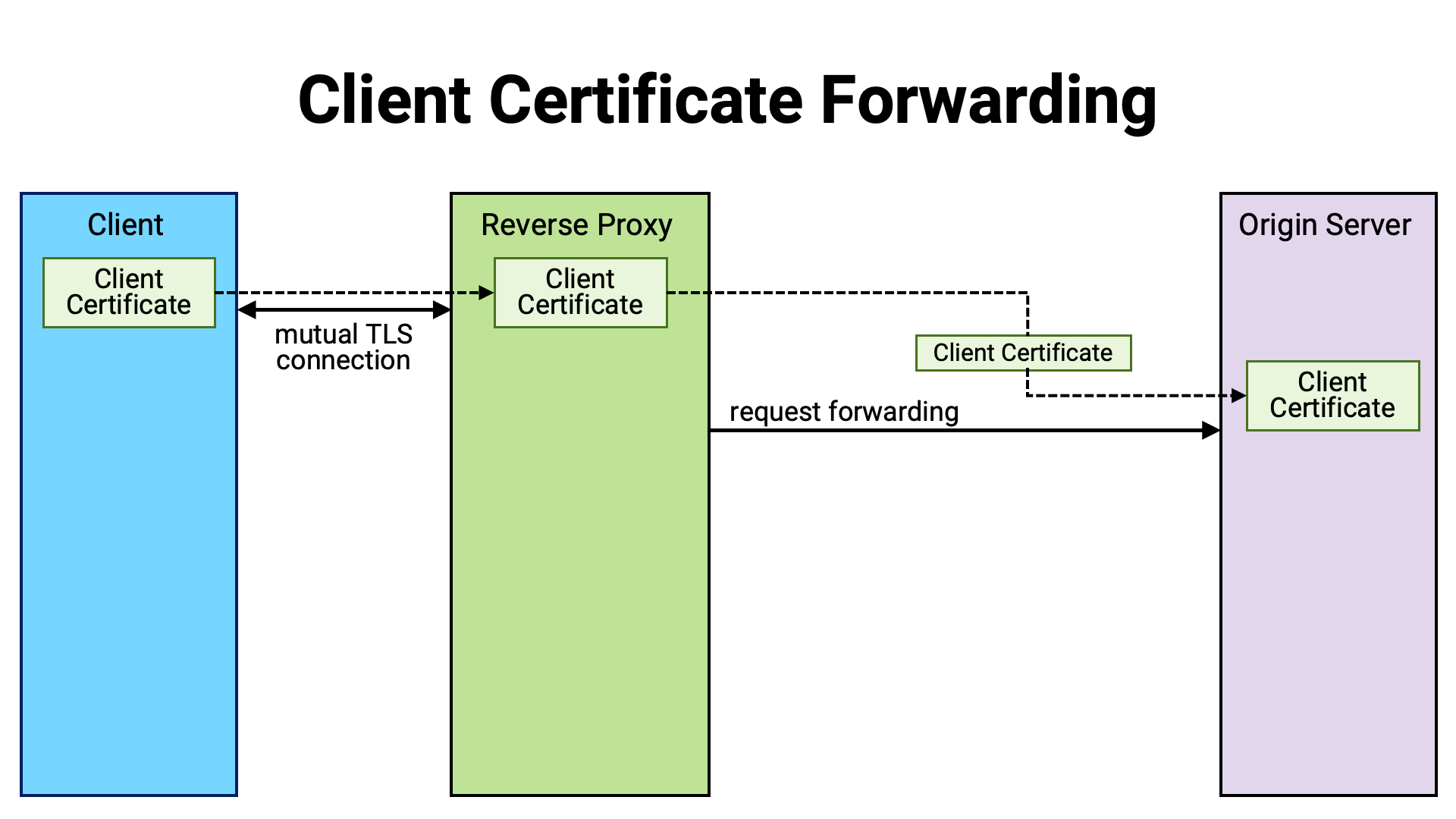
For this purpose, a common practice has long been to add a custom HTTP
header—containing the client certificate as its value (for example,
X-Ssl-Cert)—to the forwarded request. RFC 9440 defines and
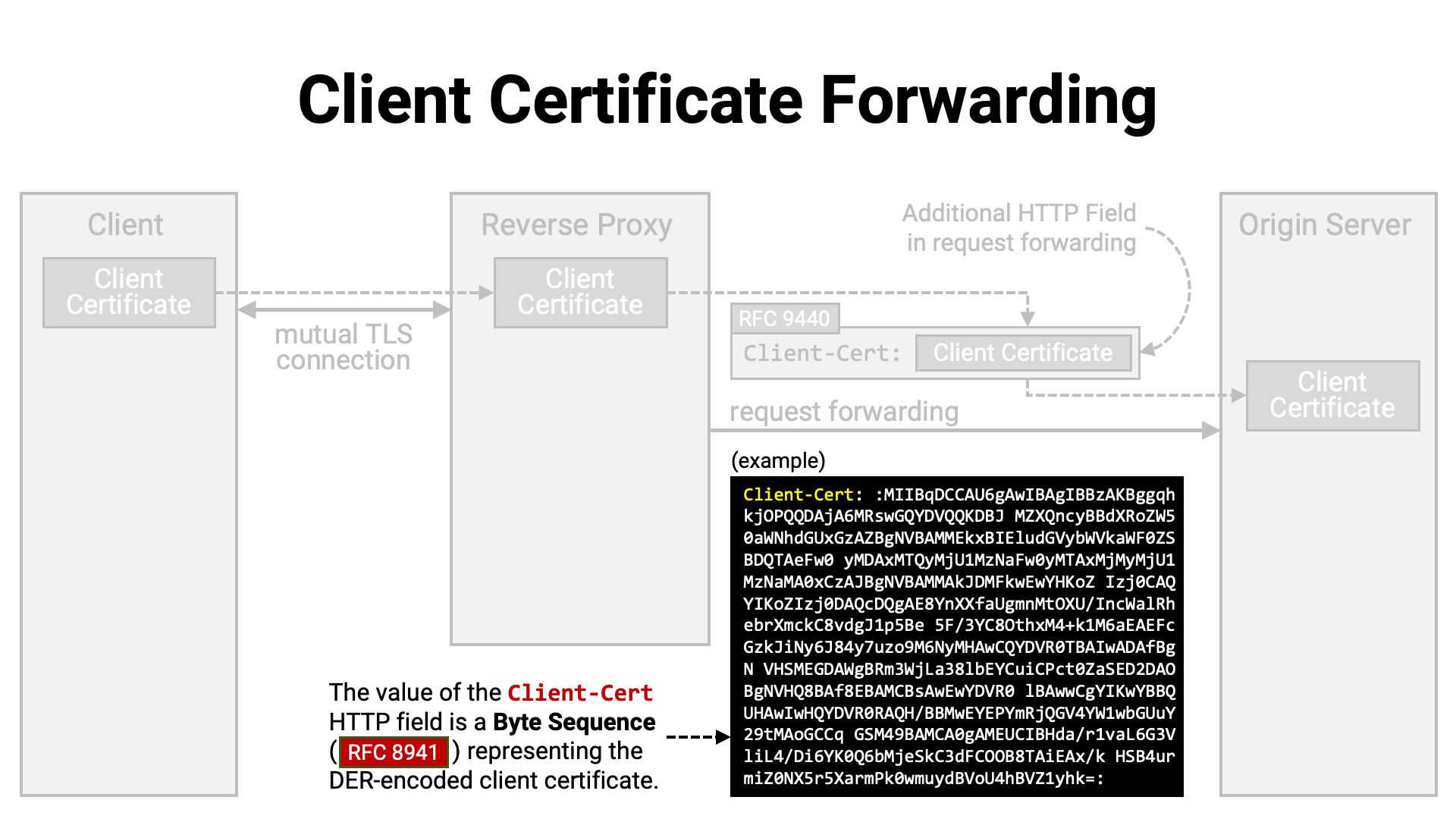
standardizes the use of Client-Cert as the name of this HTTP header.
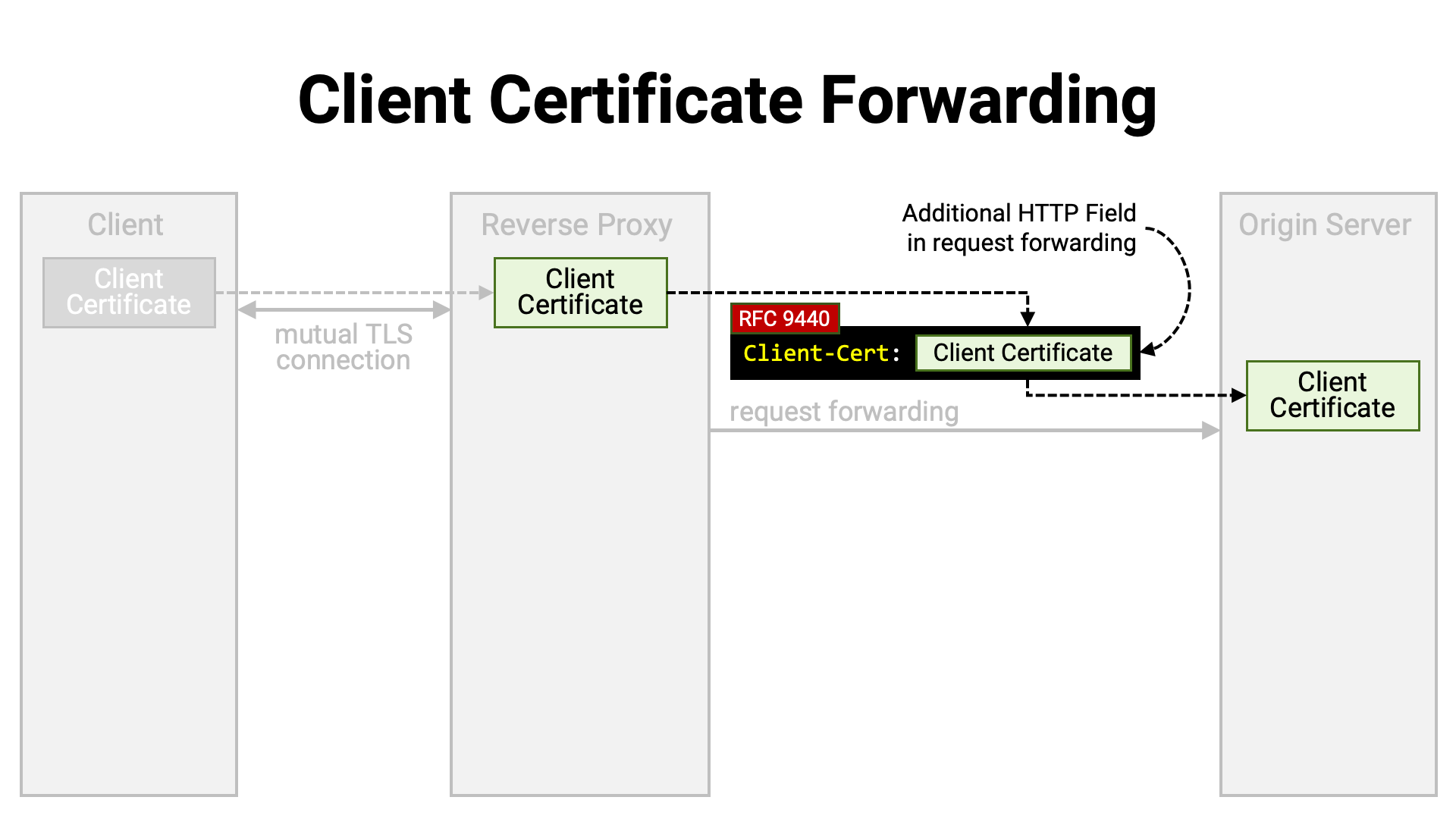
RFC 9440 also standardized the format used when embedding a client
certificate as the value of an HTTP header. Previously, many implementations
used the PEM format (RFC 7468), but there were variations—such as
whether line breaks were present, or whether BEGIN / END boundaries were
included—resulting in low interoperability. RFC 9440 specifies the
format as “a byte sequence (RFC 8941 Section 3.3.5)
representing the DER-encoded (X.690) client certificate.”
Summary:
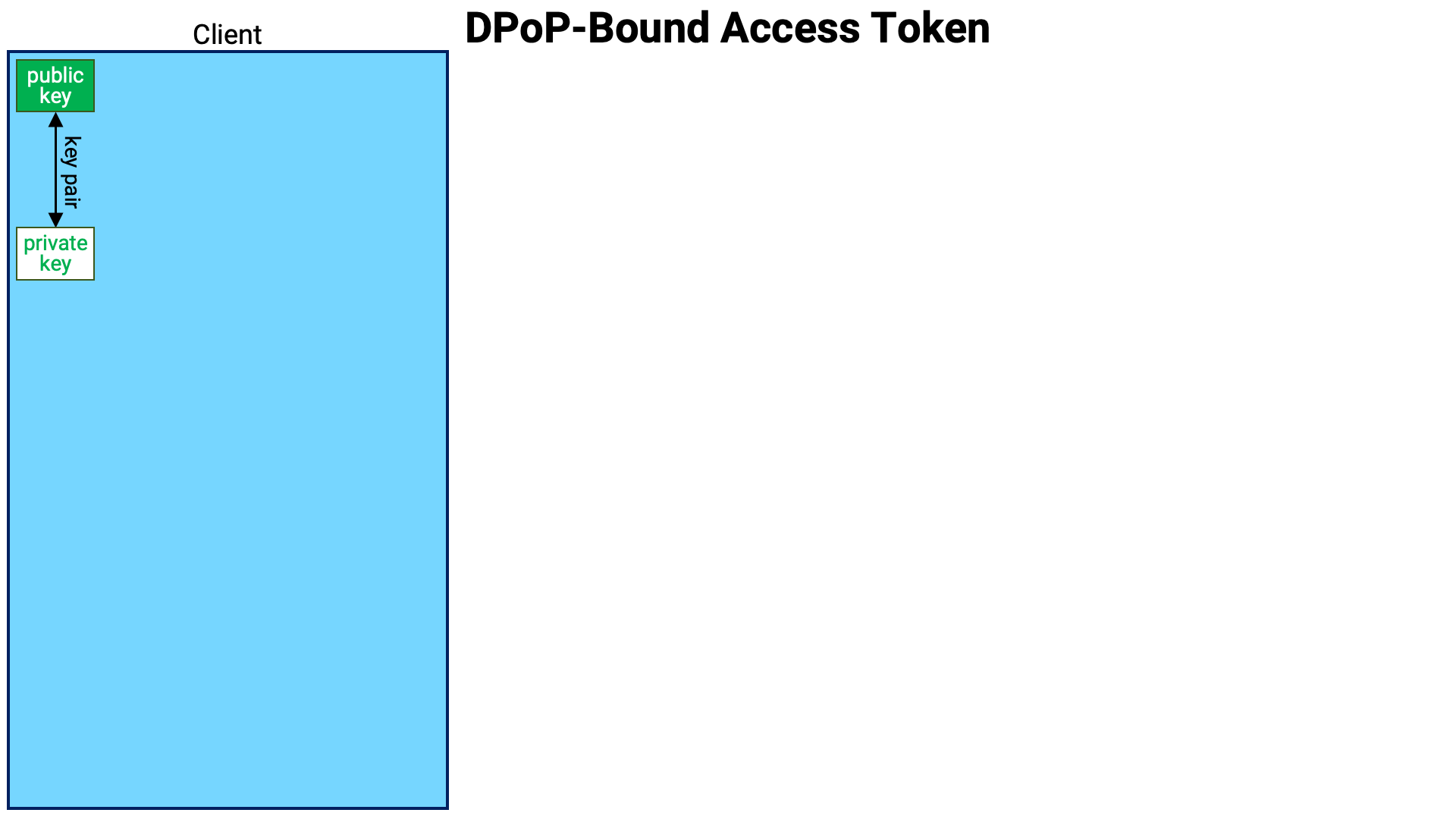
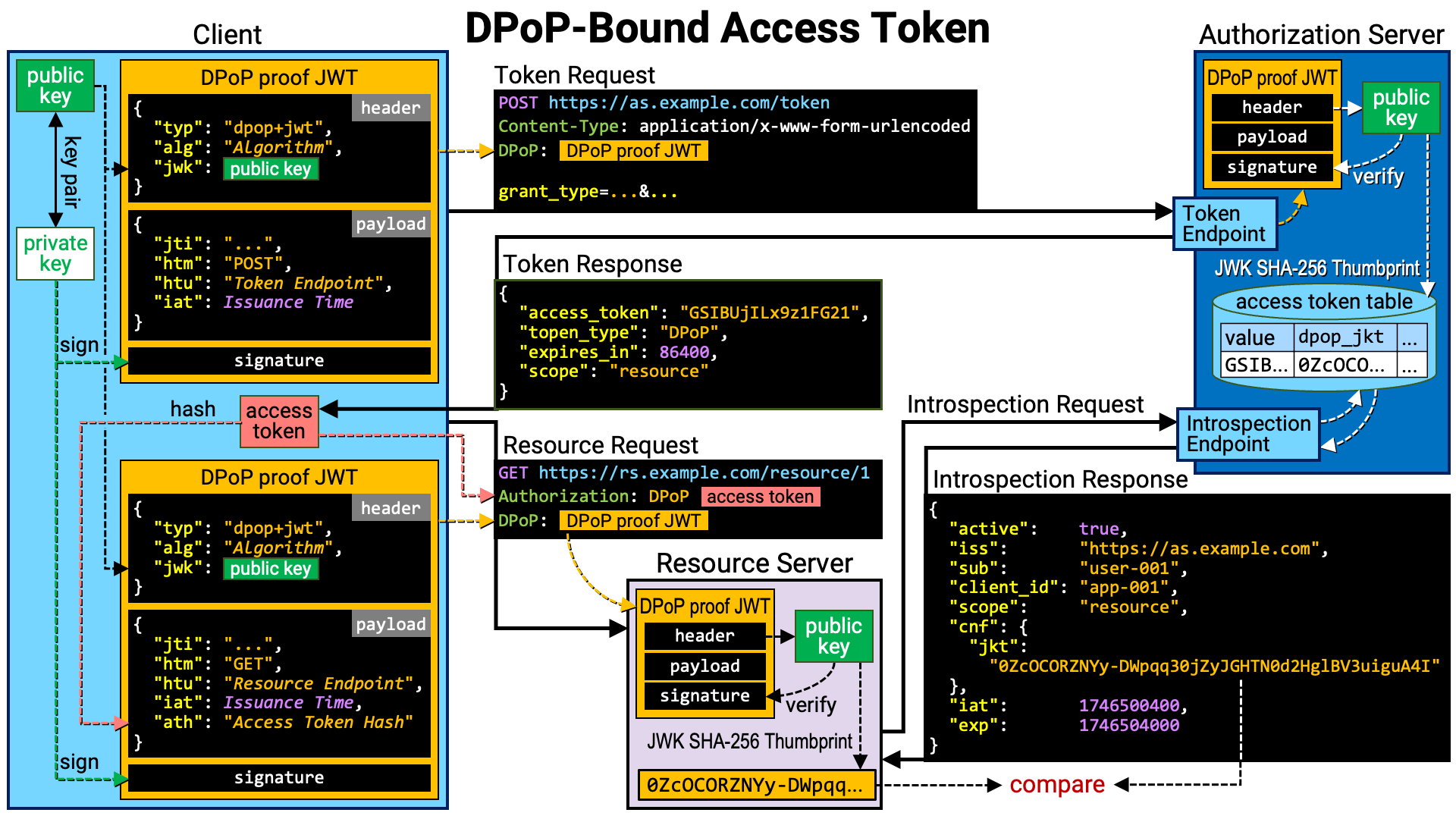
RFC 9449, commonly referred to as DPoP, is one method for implementing sender-constrained access tokens.
In DPoP, at the time of access token issuance, the public key from a key pair prepared by the client application is bound to the access token. Then, when the access token is used, the client is also required to present “proof” that it possesses the private key corresponding to the public key bound to the access token, thereby enforcing the sender constraint.
This proof is generated by signing data—into which the public key is embedded—with the corresponding private key. In other words, it is a self-signed token.
The recipient of the self-signed token extracts the embedded public key and verifies the token’s signature using that public key. If the verification succeeds, it can be concluded that the entity that generated the token possesses the corresponding private key.
Let us now take a closer look at the detailed steps of DPoP.
The client application first generates a key pair. The public key of this key pair will be bound to the access token generated in the subsequent process.
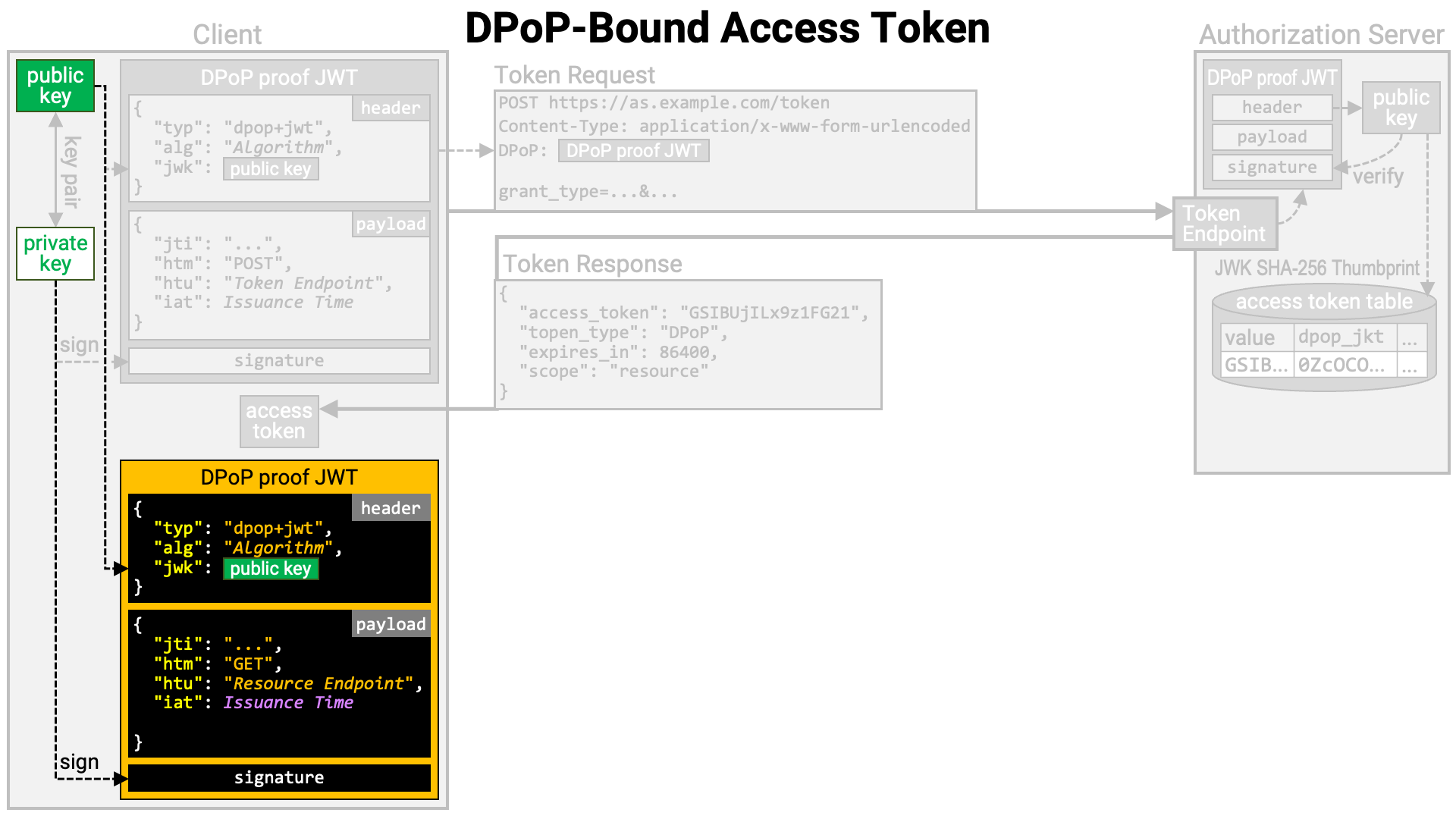
Next, the client creates a PoP. In RFC 9449, this PoP is called a DPoP proof JWT, and its structure is precisely defined. The key points are as follows:
typ header parameter value is dpop+jwt.jwk header parameter contains the public key to be bound to the access token.htm claim value is the HTTP method of the request to be sent.htu claim value is the target URI of the request to be sent (excluding query and fragment parameters).jti claim and iat claim are also required.jwk header parameter.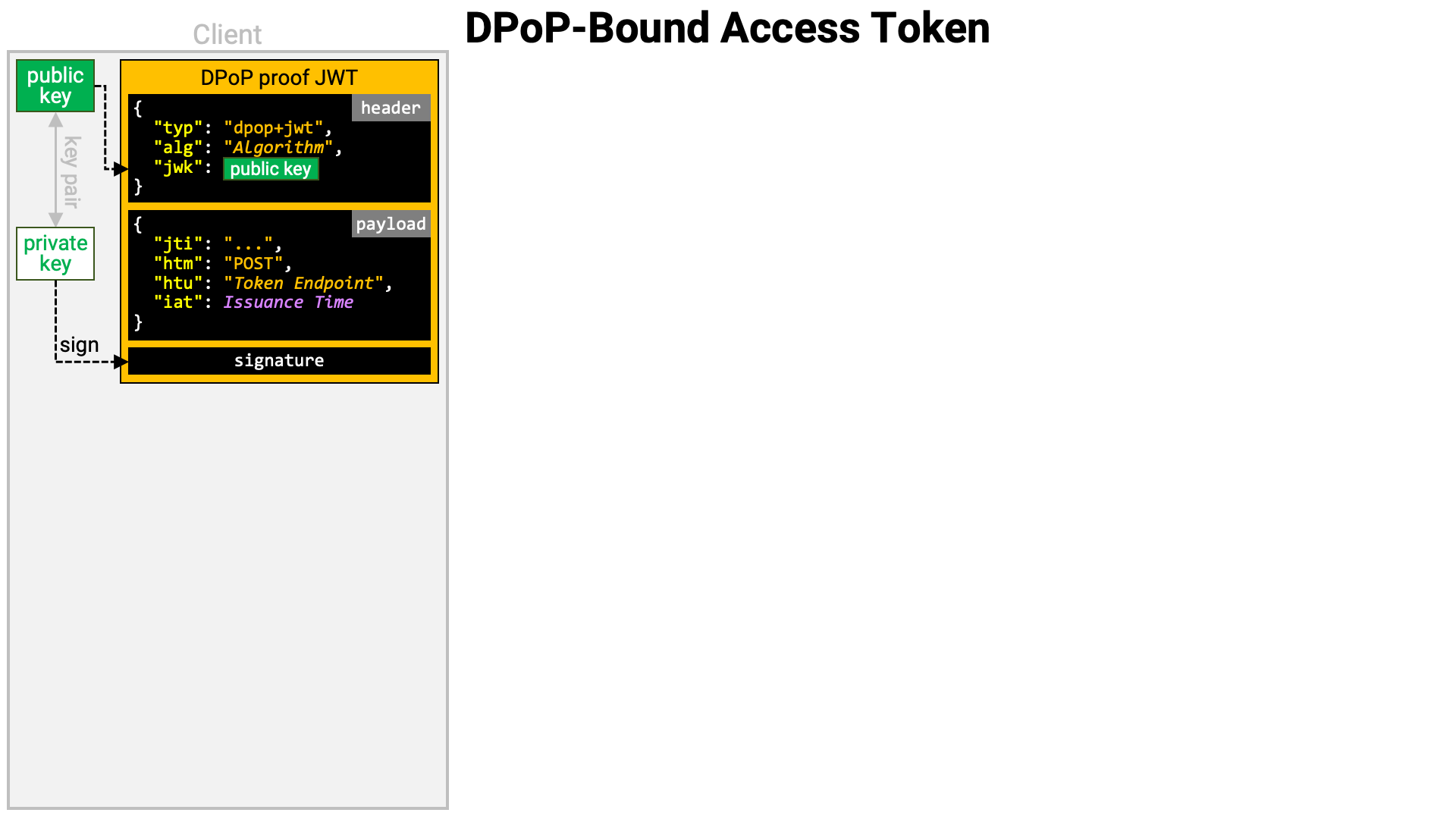
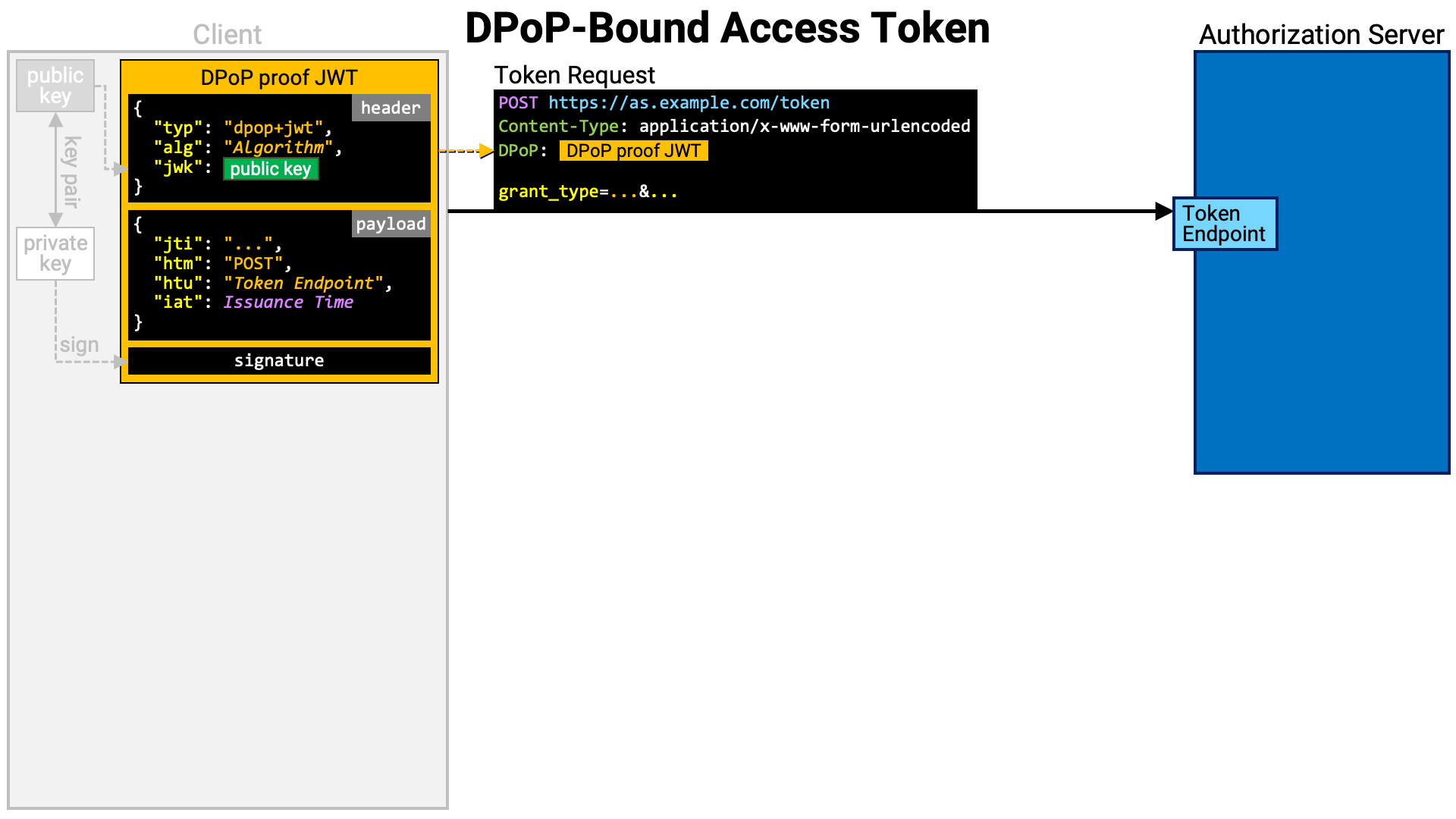
The client sends a token request to the authorization server’s token endpoint.
At this time, it includes the previously created DPoP proof JWT in the DPoP
header of the request.
The implementation of the authorization server’s token endpoint extracts the DPoP proof JWT from the token request.
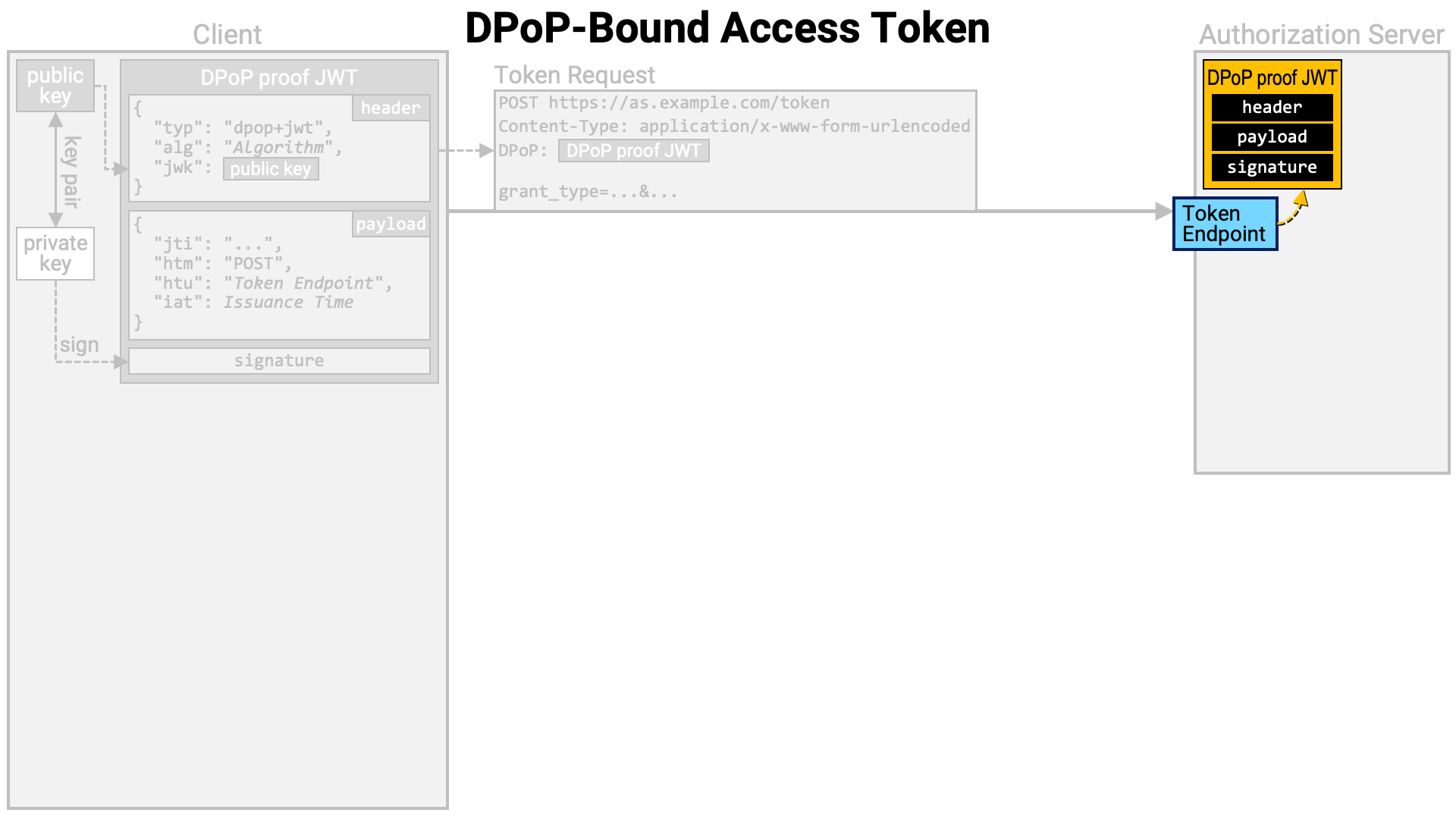
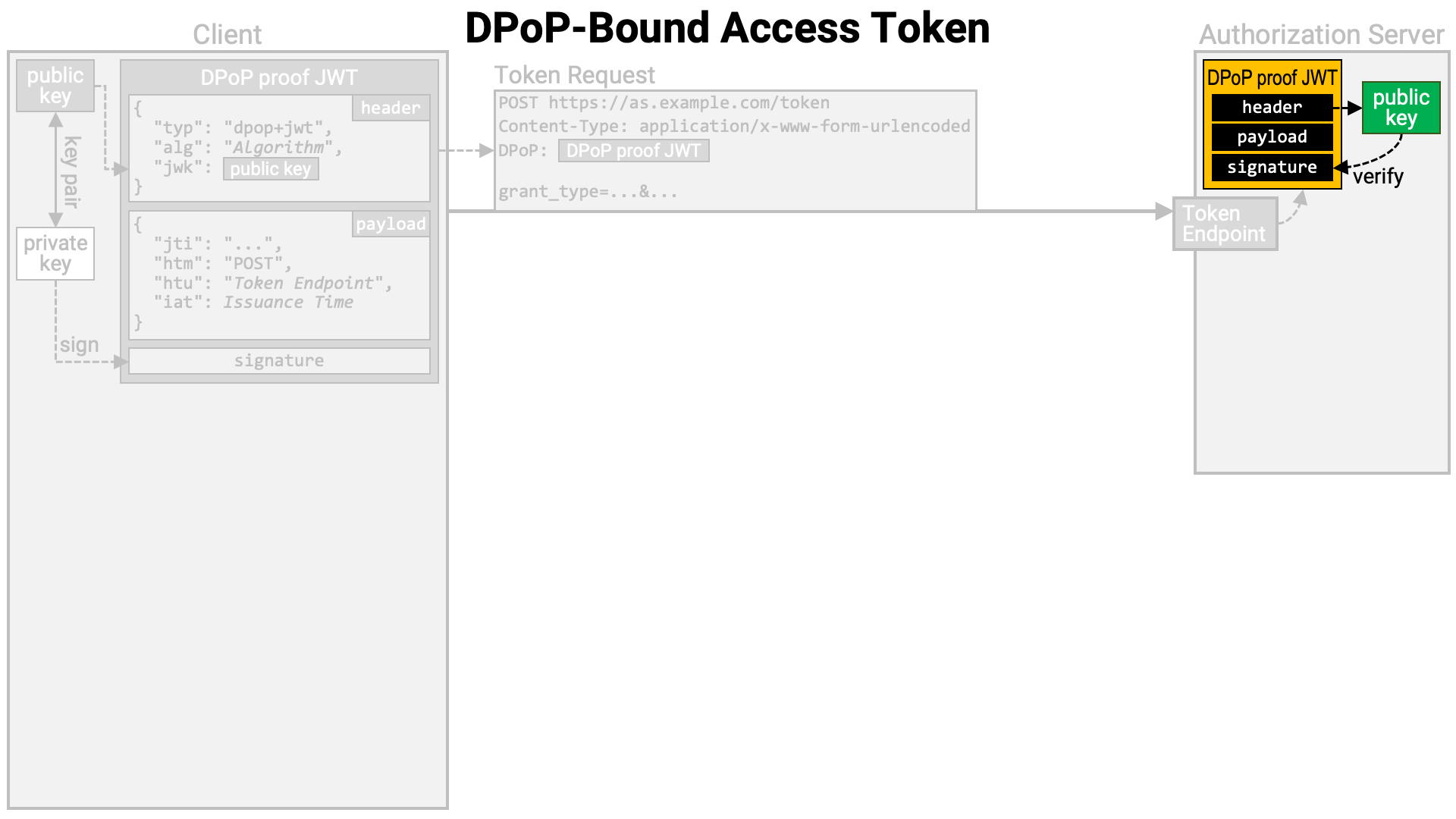
It retrieves the public key from the header of the DPoP proof JWT and verifies the JWT’s signature using that public key.
It then generates an access token if the token request is valid and stores it in the database. However, if the access token is self-contained (e.g., a JWT access token), it is possible to implement the system without writing data to the database.
At this point, the authorization server computes the JWK Thumbprint (RFC 7638) of the public key with the hash function SHA-256 (NIST FIPS 180-4), and associates it with the access token.
An access token that is bound to the public key embedded in the DPoP proof JWT in this way is called a “DPoP-bound” access token.
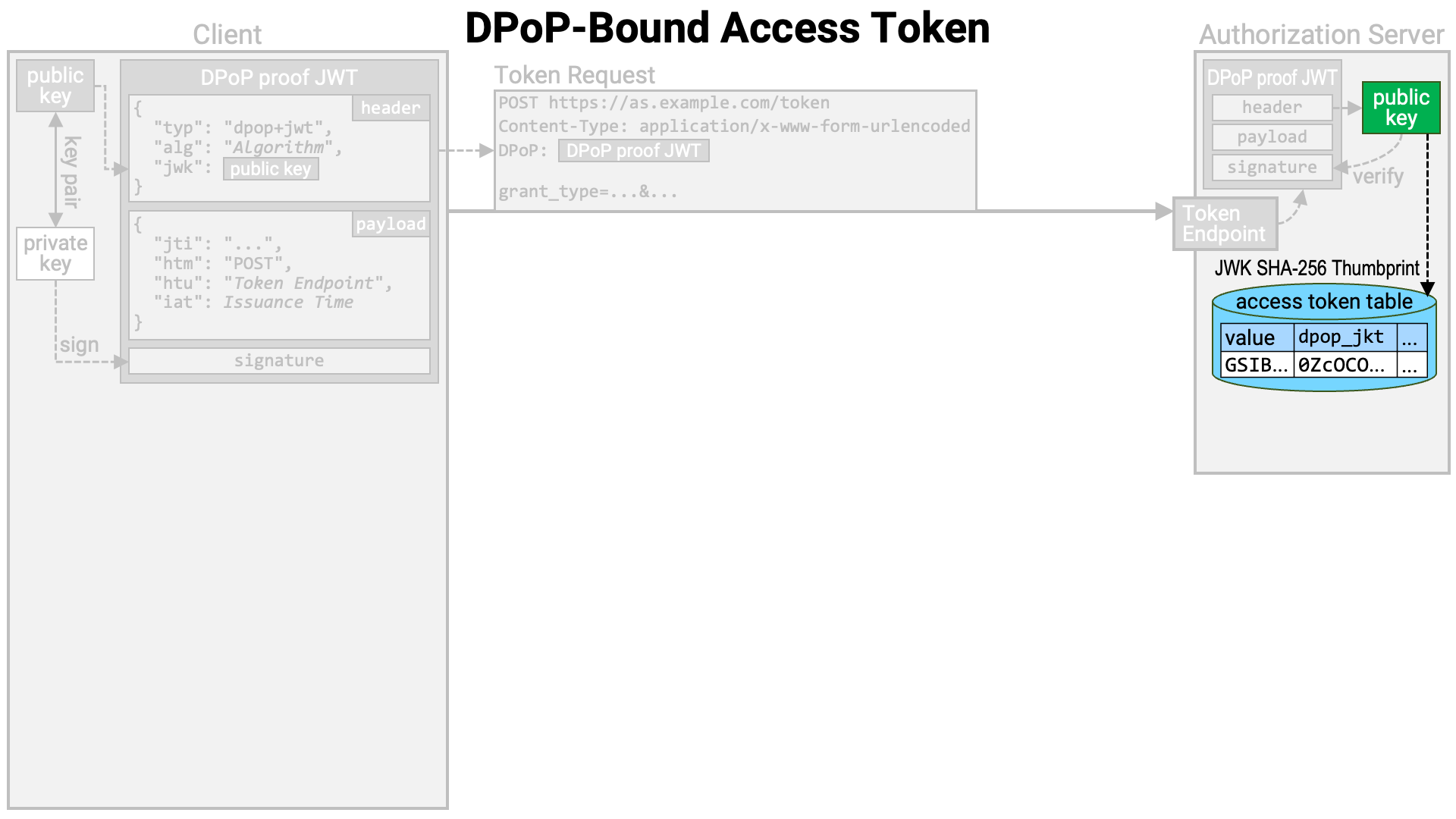
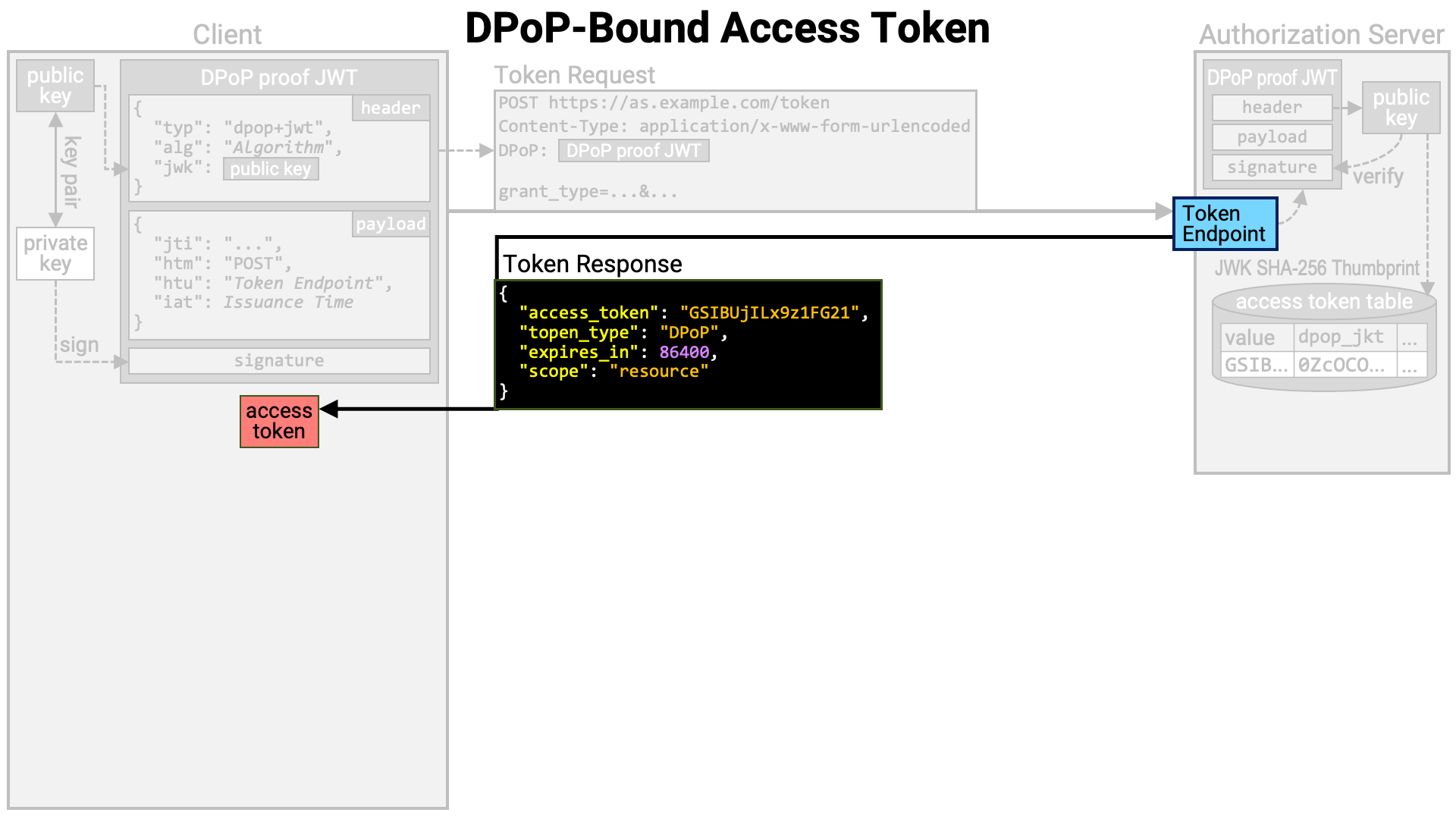
The token endpoint returns a token response containing the generated access token to the client application.
Before making a resource request, the client application creates a DPoP proof JWT.
When using a DPoP proof JWT together with an access token, the SHA-256 hash of
the access token, encoded in base64url (RFC 4648), must be included
as the value of the ath claim in the JWT payload.
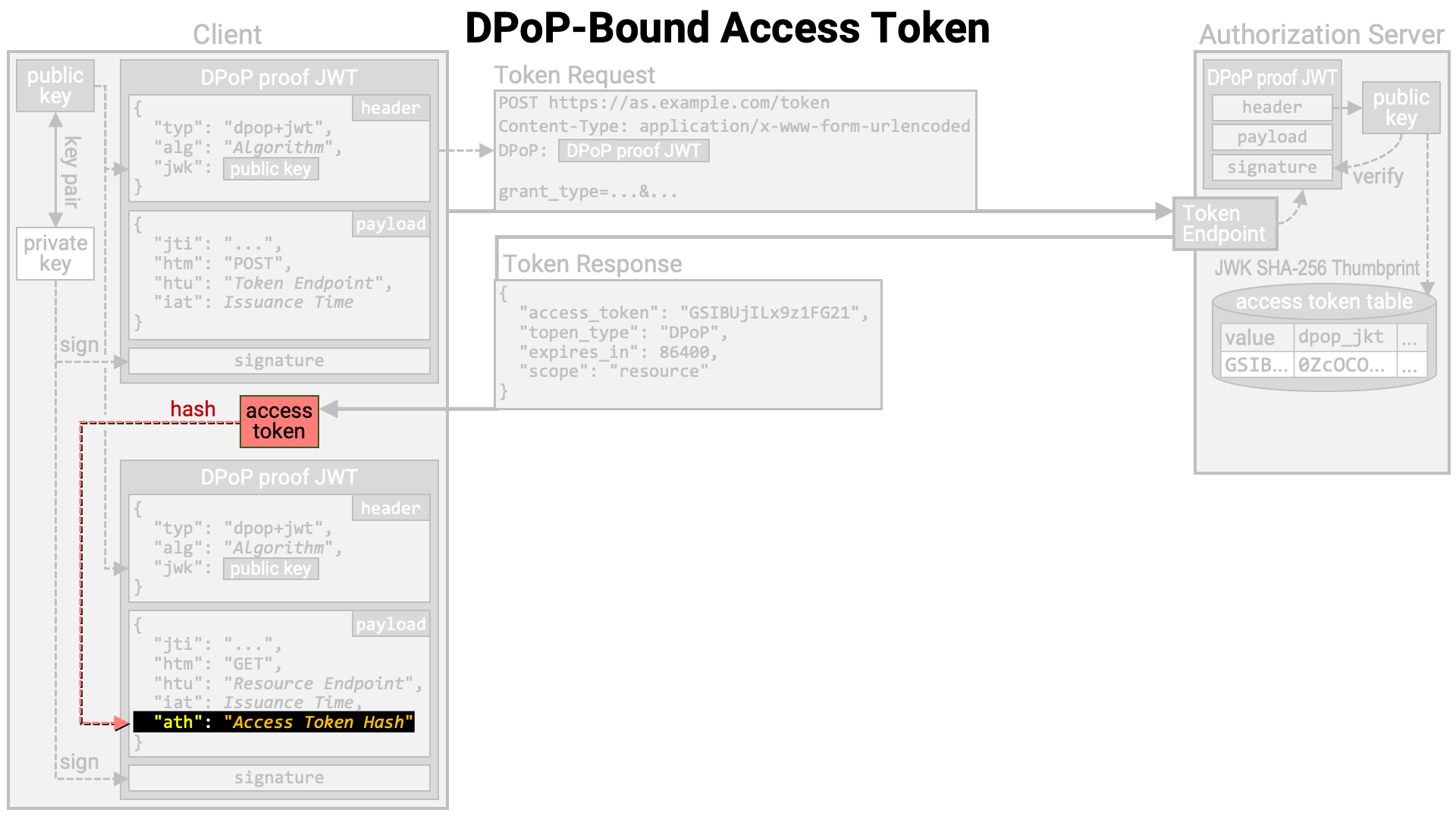
Once the DPoP proof JWT is prepared, the client makes the resource request.
The access token is included in the Authorization header, and the DPoP proof
JWT is included in the DPoP header. Note that the scheme part of the
Authorization header value should be DPoP (not Bearer as specified in
RFC 6750).
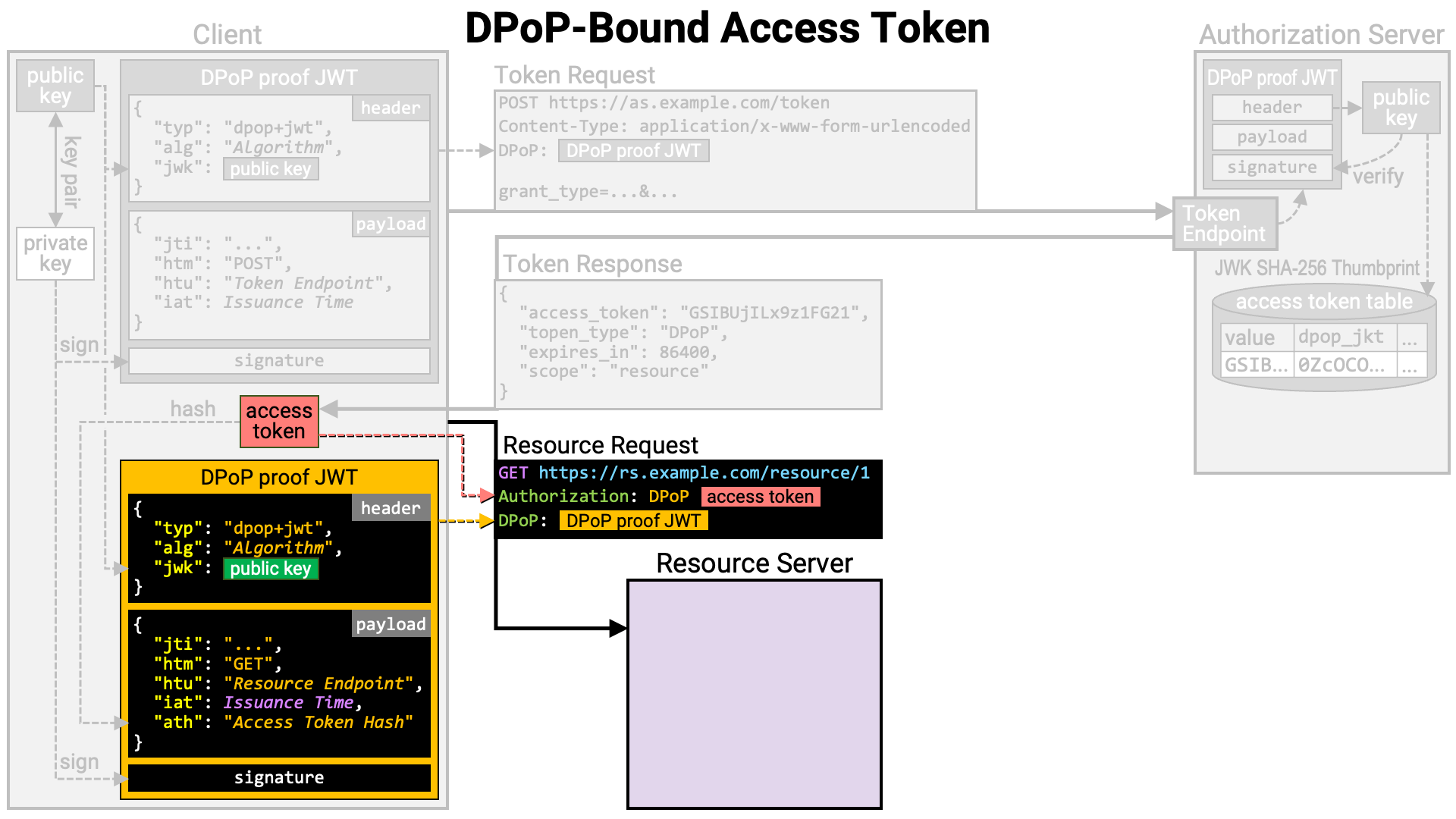
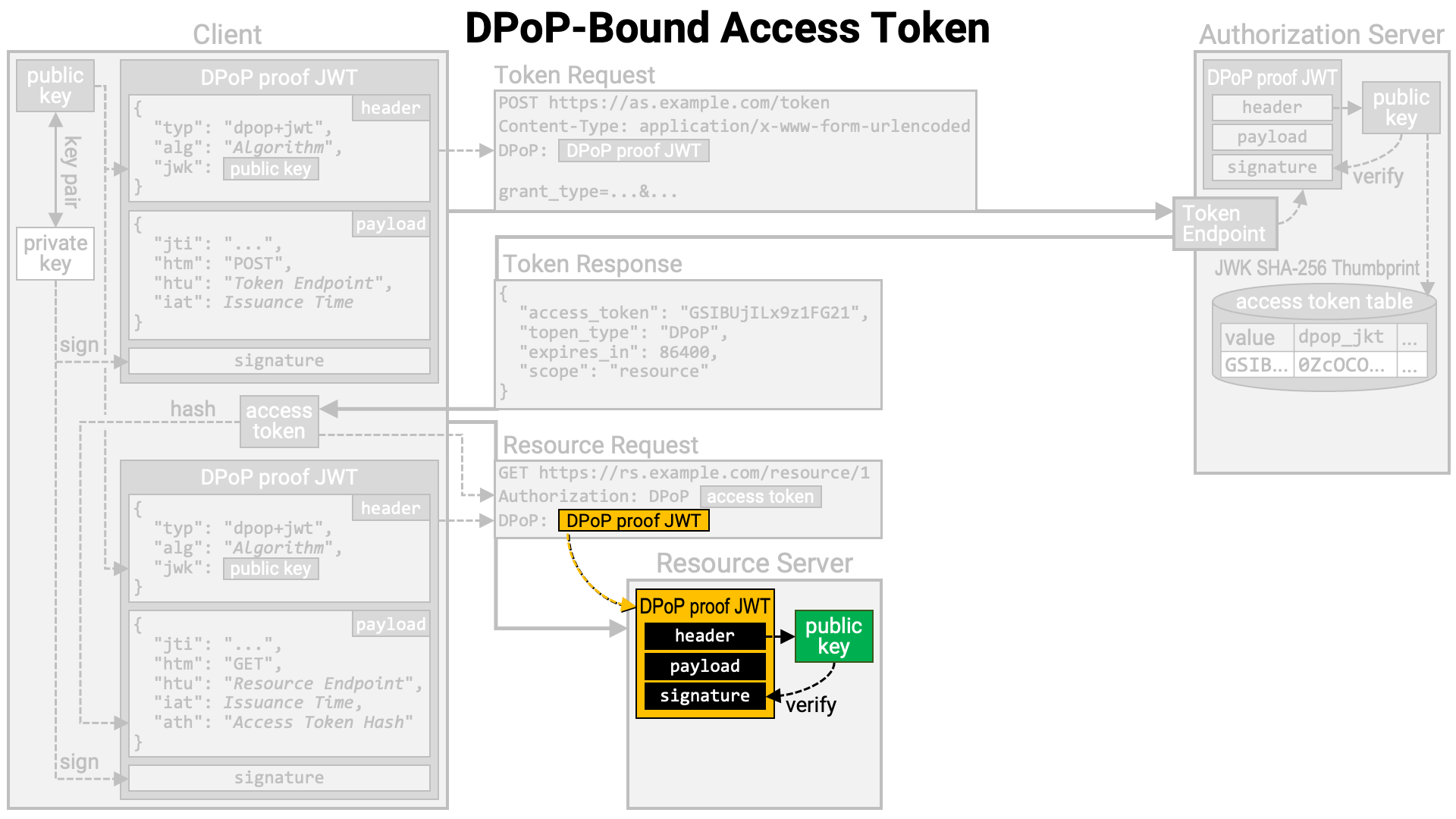
The resource server receiving the resource request extracts the DPoP proof JWT from the request and verifies its signature using the public key embedded in the JWT header.
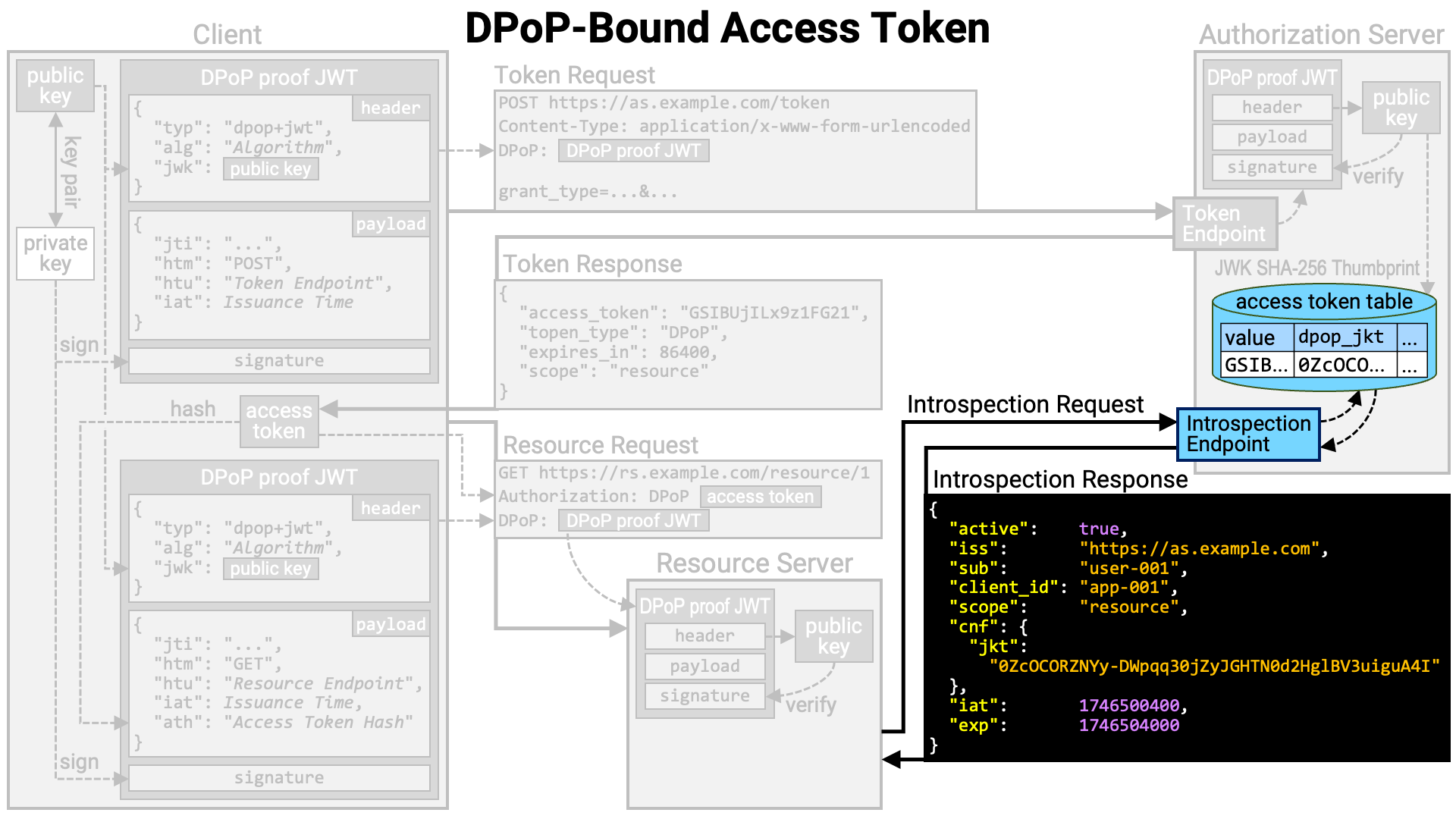
The resource server queries the authorization server’s introspection endpoint
to obtain information about the access token. If the access token is DPoP-bound,
the introspection endpoint includes the JWK Thumbprint of the associated public
key in the introspection response, as the value of the jkt sub-property
within the cnf property (RFC 7800).
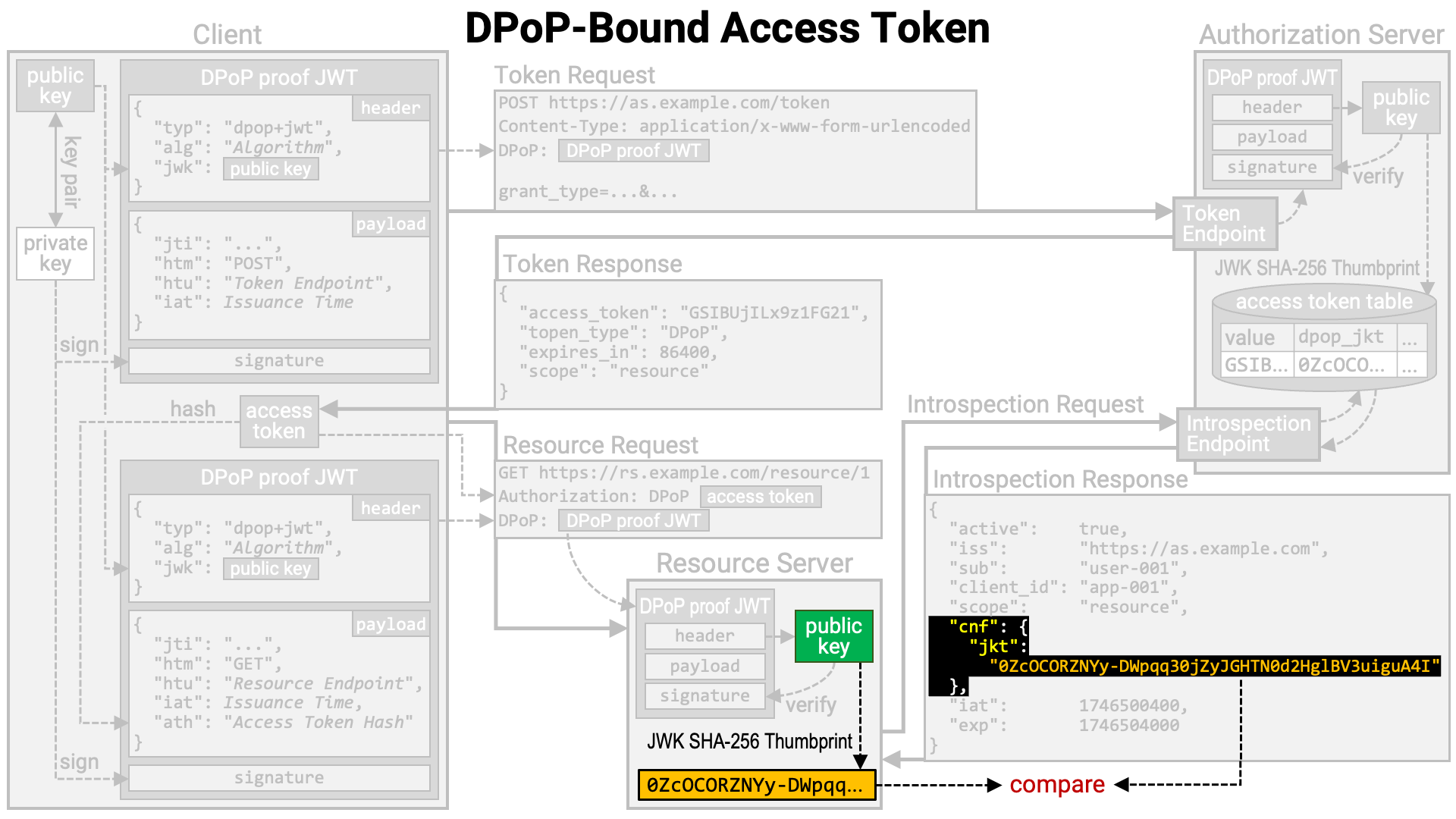
The resource server calculates the JWK Thumbprint of the public key contained in the DPoP proof JWT and verifies whether it matches the value in the introspection response. If they do not match, the resource server determines that the client application making the resource request is not the legitimate holder of the access token and rejects the resource request.
Summary:
A server may require that a nonce value it provides be included in the DPoP proof JWT. By setting a lifetime for the nonce value, the server can control the validity period of the DPoP proof JWT (RFC 9449 Section 8); by making the nonce value unpredictable, the server can make it more difficult to pre-generate a DPoP proof JWT and use it elsewhere (RFC 9449 Section 11.2). Requiring a nonce has security advantages like these.
If a DPoP proof JWT without a nonce claim is sent to a resource server that
requires a nonce, a use_dpop_nonce error will be returned with a DPoP-Nonce
header.
HTTP/1.1 401 Unauthorized
WWW-Authenticate: DPoP error="use_dpop_nonce"
DPoP-Nonce: ZgmFr7UWLrJX0fHB
Upon receiving this error, the client application extracts the value from the
DPoP-Nonce header and creates a DPoP proof JWT that includes this value as
the nonce claim. It then resends the resource request with the newly created
DPoP proof JWT attached.

The client application continues to use the same nonce value in subsequent
resource requests. However, the nonce will eventually expire. Therefore, if
the same nonce is used continuously, the server will ultimately return an
invalid_dpop_proof error.
HTTP/1.1 401 Unauthorized
WWW-Authenticate: DPoP error="invalid_dpop_proof"
DPoP-Nonce: HDoSFcMWFrfcWdr3
If the error response contains a DPoP-Nonce header whose value differs from
the nonce value previously used, it is possible that the error was caused by
the nonce being outdated. In this case, it is worth regenerating the DPoP proof
JWT and attempting to resend the resource request.
If a resource server supports DPoP, it must ensure that the value of the htu
claim in a received DPoP proof JWT matches the target URI of the request
(excluding the query and fragment parameters). To perform this check, the
resource server needs to know the absolute URI of the request.
Similarly, if the resource server supports HTTP Message Signatures
(RFC 9421), it needs the absolute URI of the request in order to
use it as the value of the @target-uri derived component
(RFC 9421 Section 2.2.2).
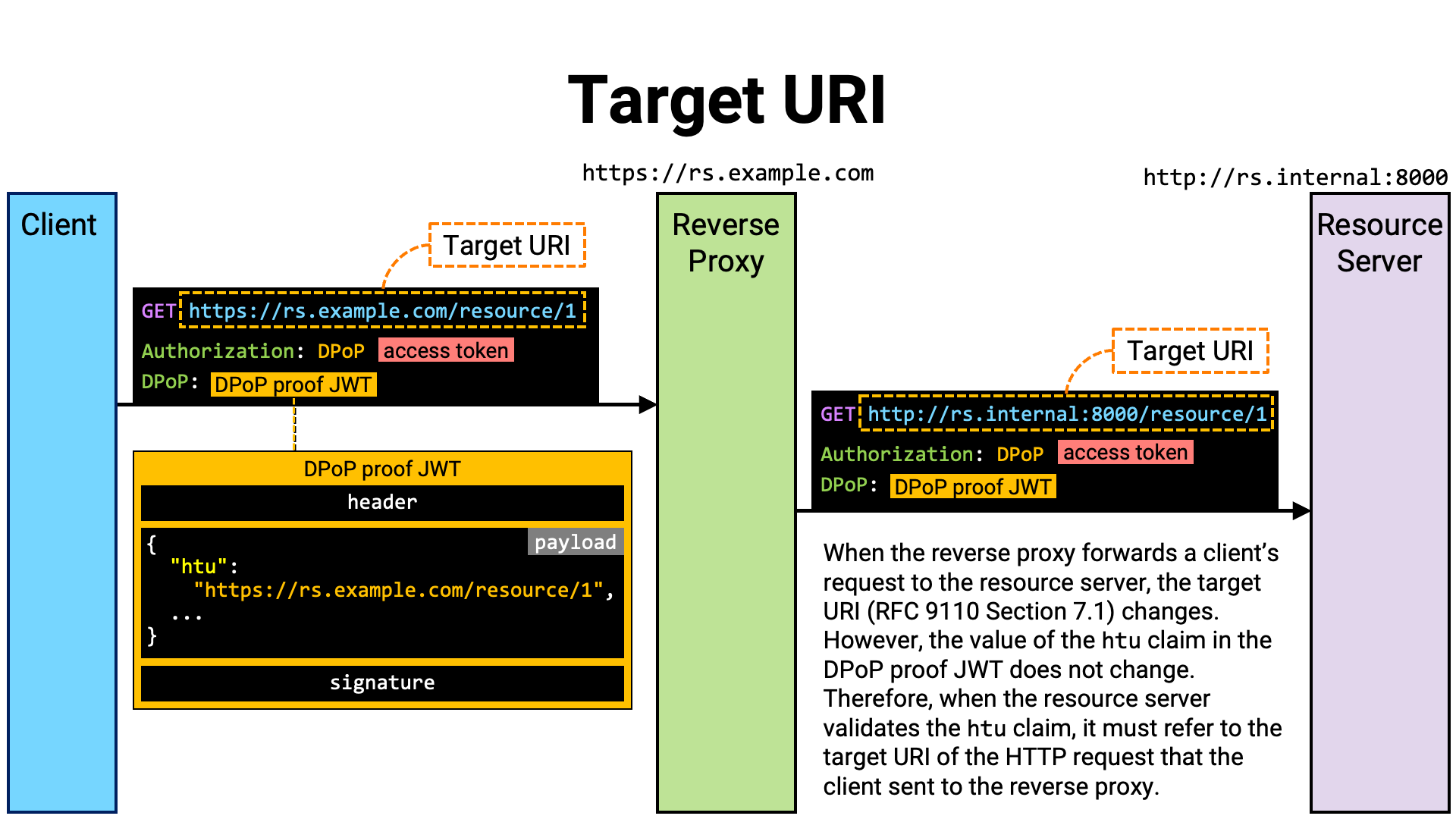
However, if the resource server is running behind a reverse proxy, it cannot directly know the absolute URI of the request. This is because the HTTP request visible to the resource server is not the one originally sent by the client application, but rather the one forwarded by the reverse proxy. In most cases, the scheme, host name, and port number differ from those of the original request (the request that the client application sent to the reverse proxy).
Since the request received by the resource server differs from the one sent by
the client, comparing the target URI of the resource server’s received request
with the htu claim in the DPoP proof JWT will not match, causing all resource
requests containing DPoP proof JWTs to be rejected. Likewise, the value of the
@target-uri derived component as seen by the client application will not
match the @target-uri as recognized by the resource server, causing HTTP
Message Signature verification to fail and all resource requests to be rejected.
Therefore, verification of DPoP proof JWTs and HTTP Message Signatures at the resource server must be based on the target URI of the request as received by the reverse proxy, rather than the target URI of the request as received by the resource server itself.
When a reverse proxy forwards an HTTP request, it is common practice to add custom HTTP headers containing information about the original HTTP request.
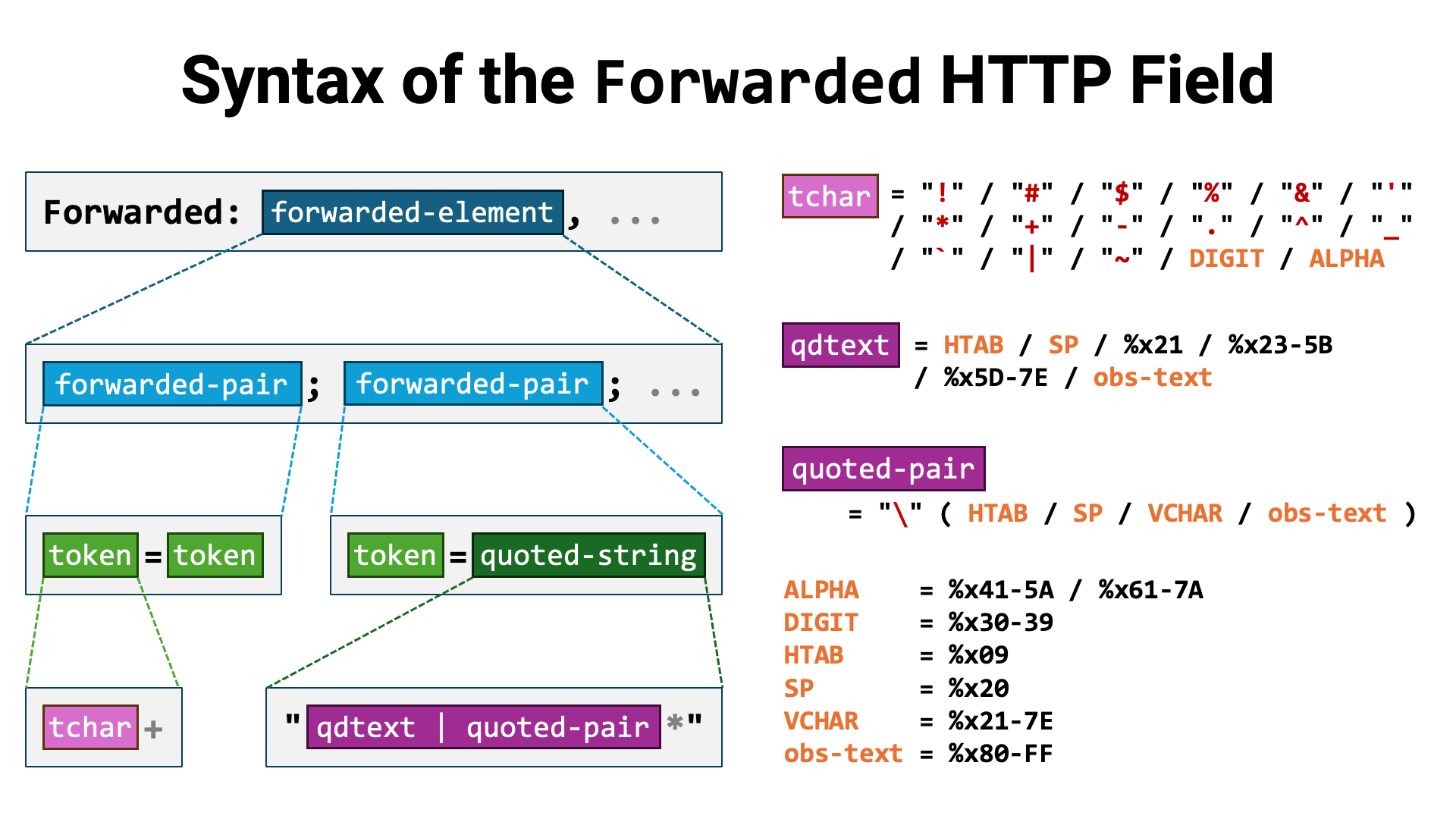
For this purpose, the Forwarded HTTP header was defined by the
RFC 7239 Forwarded HTTP Extension. For example, to convey that the
scheme of the original request was https and the host name was
rs., the reverse proxy would add a
Forwarded header like the following:
Forwarded: proto=https;host=rs.example.com
The Forwarded HTTP header standardized what had previously been achieved
using non-standard HTTP fields such as X-Forwarded-For, X-Forwarded-By,
and X-Forwarded-Proto. Therefore, the use of the Forwarded header is
recommended.
However, the syntax of the Forwarded header value is unexpectedly complex.
While it is not impossible, parsing it with regular expressions is difficult,
and since it does not conform to the general syntax defined in
RFC 8941, generic libraries cannot be used either. In the end,
you need to implement a dedicated parser specifically for the Forwarded HTTP
header (e.g., http-field-parser).
Therefore, custom HTTP headers that are easier to process are still widely used. Below are examples of such custom HTTP headers.
| Header Name | Reference |
|---|---|
Front-End-Https |
[Microsoft] Helping to Secure Communication: Client to Front-End Server |
X-Forwarded-For |
MDN Web Docs / X-Forwarded-For |
X-Forwarded-Host |
MDN Web Docs / X-Forwarded-Host |
X-Forwarded-Port |
[AWS] HTTP headers and Classic Load Balancers # X-Forwarded-Port |
X-Forwarded-Proto |
MDN Web Docs / X-Forwarded-Proto |
X-Forwarded-Protocol |
MDN Web Docs / X-Forwarded-Proto |
X-Forwarded-Ssl |
MDN Web Docs / X-Forwarded-Proto |
X-Url-Scheme |
MDN Web Docs / X-Forwarded-Proto |
However, the standardized Forwarded HTTP header or widely used custom HTTP
headers are incomplete as a means of determining the target URI, since they
do not include information about the path or query components.
To use the @target-uri derived component in HTTP Message Signatures, query
component information is required. Unfortunately, as of now, there is no
standardized header or widely adopted custom header that conveys the absolute
URL including the path and query components.
It would be desirable to see the adoption of some kind of custom HTTP header
that represents the absolute URL (e.g., X-Forwarded-URL), the definition of
a standardized HTTP header (e.g., Target-URI), or the addition of a new
HTTP Forwarded Parameter.
It is common for HTTP messages to be delivered via multiple intermediary servers. During this relay process, operations such as TLS termination or the addition, consolidation, and modification of HTTP headers are often performed. Under such conditions, methods to ensure the integrity and authenticity of HTTP messages end-to-end between the sender and the recipient have long been studied.
In general, digital signatures are the means to achieve integrity and authenticity. However, in the case of HTTP messages, since parts of the message may be modified during transit, simply signing the entire HTTP message does not work. Therefore, it is necessary to select only the portions meaningful to both the sender and the recipient, normalize them so as not to be affected by intermediary modifications, and then apply a signature to that subset.
For this purpose, numerous competing proposals emerged, some of which were actually implemented and deployed. Ultimately, the specification adopted by the IETF became RFC 9421 HTTP Message Signatures.
In RFC 9421, the portions of an HTTP message that can be part of the signature input are referred to as HTTP message components.
The most straightforward HTTP message components are HTTP fields. For example,
the Content-Type HTTP field and the Date HTTP field are both HTTP message
components.
There are also HTTP message components derived from attributes other than HTTP fields. These are called derived components. The HTTP method, target URI, and HTTP status code are all examples of derived components.
The choice of which components to include in a signature is left up to the application, depending on its particular purpose. For instance, the FAPI 2.0 HTTP Signatures specification requires that the following components be included in the signature when signing an HTTP request:
Authorization HTTP fieldDPoP HTTP field (if present)Content-Digest HTTP field (if the message has a body)In HTTP message signatures, the string that serves as the input to the digital signature is called the signature base. The signature base consists of a list of identifier–value pairs of HTTP message components to be signed, followed by metadata about the signature itself.
Before generating or verifying an HTTP message signature, the signature base must first be constructed. For the precise syntax of the signature base, see RFC 9421, Section 2.5. Creating the Signature Base.
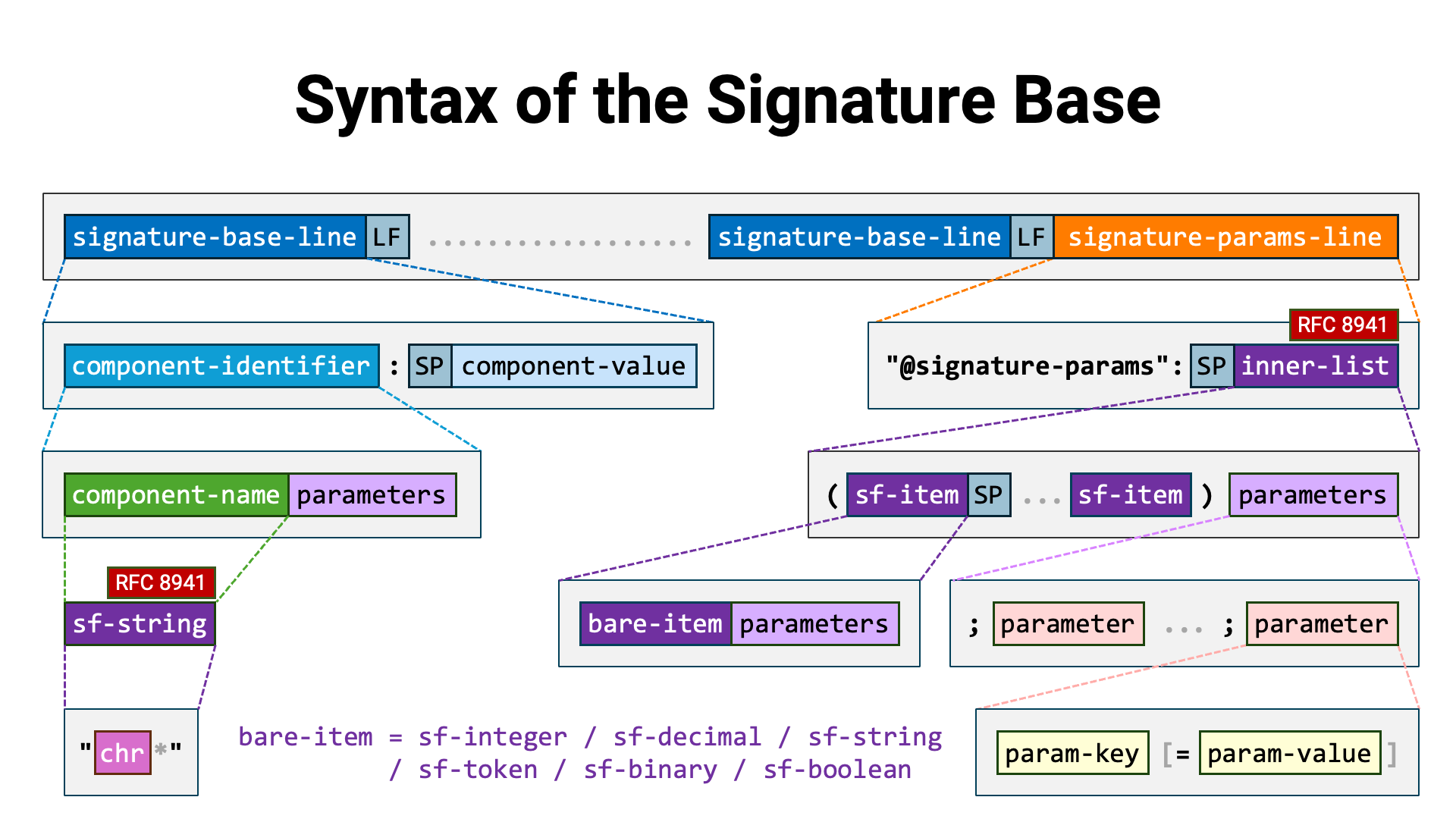
Here is an example of a signature base excerpted from RFC 9421:
"@method": POST
"@authority": example.com
"@path": /foo
"content-digest": sha-512=:WZDPaVn/7XgHaAy8pmojAkGWoRx2UFChF41A2svX+TaPm+AbwAgBWnrIiYllu7BNNyealdVLvRwEmTHWXvJwew==:
"content-length": 18
"content-type": application/json
"@signature-params": ("@method" "@authority" "@path" "content-digest" "content-length" "content-type");created=1618884473;keyid="test-key-rsa-pss"
In this example of a signature base, lines 1 through 3 consist of
identifier–value pairs of derived components. The component names of derived
components begin with @, such as @method. Lines 4 through 6, on the other
hand, consist of HTTP fields and their values.
The final line of the signature base (line 7 in this example) contains metadata
about the signature. It always begins with "@signature-params":, followed by
an Inner List (RFC 8941 Section 3.1.1). This Inner List
enumerates the component identifiers of the HTTP message components included in
the signature. In this example, the following six are listed:
"@method""@authority""@path""content-digest""content-length""content-type"The portion that follows the list of component identifiers in parentheses,
beginning with a semicolon (;), represents the optional parameters of the
Inner List. In this example, the created parameter and the keyid parameter
are included. These parameters are defined in
RFC 9421 Section 2.3.
The signing method abstractly represented as HTTP_SIGN in
RFC 9421 Section 3.3 takes the signature base (M) and the
signing key (Ks) as input and produces the signature (S) as output.
HTTP_SIGN (M, Ks) -> S
RFC 9421 Section 3.3 lists the signature algorithms, and the HTTP Signature Algorithms registry maintained by IANA contains the following set of algorithms.
| Algorithm Name | Description | Reference |
|---|---|---|
rsa-pss-sha512 |
RSASSA-PSS using SHA-512 | RFC 9421, Section 3.3.1 |
rsa-v1_5-sha256 |
RSASSA-PKCS1-v1_5 using SHA-256 | RFC 9421, Section 3.3.2 |
hmac-sha256 |
HMAC using SHA-256 | RFC 9421, Section 3.3.3 |
ecdsa-p256-sha256 |
ECDSA using curve P-256 DSS and SHA-256 | RFC 9421, Section 3.3.4 |
ecdsa-p384-sha384 |
ECDSA using curve P-384 DSS and SHA-384 | RFC 9421, Section 3.3.5 |
ed25519 |
EdDSA using curve edwards25519 | RFC 9421, Section 3.3.6 |
Regarding the set of JWS algorithms familiar in the context of OAuth 2.0 and OpenID Connect, they are explicitly mentioned in RFC 9421 Section 3.3.7. JSON Web Signature (JWS) Algorithms. When these algorithms are used, it is specified that the signature base must be used as the “JWS Signing Input” (RFC 7515).
Since HTTP message signatures do not have anything equivalent to a JWS header,
the signature algorithm must be conveyed to the verifier by some other means.
For this purpose, it seems appropriate to use the alg parameter defined in
RFC 9421 Section 2.3. However, because the final paragraph of
RFC 9421 Section 3.3.7 explicitly states otherwise, the alg
parameter is not used.
JSON Web Algorithm (JWA) values from the “JSON Web Signature and Encryption Algorithms” registry are not included as signature parameters. Typically, the JWS algorithm can be signaled using JSON Web Keys (JWKs) or other mechanisms common to JOSE implementations. In fact, JWA values are not registered in the “HTTP Signature Algorithms” registry (Section 6.2), and so the explicit
algsignature parameter is not used at all when using JOSE signing algorithms.
The verification method abstractly represented as HTTP_VERIFY in
RFC 9421 Section 3.3 takes the signature base (M), the
verification key (Kv), and the signature (S) as inputs, and produces the
verification result (V) as output.
HTTP_VERIFY (M, Kv, S) -> V
Among the inputs to the verification process, the verification key is not included in the HTTP message and therefore must be obtained by some means. However, RFC 9421 does not define how it should be obtained.
When a resource server attempts to verify an HTTP message signature on an HTTP request, at first glance it may appear possible to obtain the verification key through the following steps:
jwks_uri metadata informationjwks_urikeyid signature parameter, identify the
verification key within the JWK SetHowever, upon closer examination, it becomes clear that in the context of a
resource server, the standard specifications alone do not provide a way to
obtain the value of the client application’s jwks_uri metadata. Excluding
individual proposed specifications, the only standard specification that could
be used is OpenID Federation (explanatory article).
However, implementing and operating this specification is a heavy undertaking,
and it cannot be said that it is widely deployed; therefore, it would not be
a general-purpose solution for obtaining verification keys.
As a result, at present, in order for a resource server to verify the HTTP message signature of an HTTP request, it must obtain the verification key using non-standard, implementation-specific methods.
HTTP message signatures are added to HTTP messages using the Signature HTTP
field and the Signature-Input HTTP field.
The value format of the Signature HTTP field is a Dictionary
(RFC 8941 Section 3.2). Each key–value pair consists of an
arbitrary label and a signature represented as a Byte Sequence
(RFC 8941 Section 3.3.5).
Signature: label=:base64-encoded-signature:, label=:base64-encoded-signature:, ...
The value format of the Signature-Input HTTP field is also a Dictionary
(RFC 8941 Section 3.2). Each key–value pair consists of an
arbitrary label and signature metadata represented as an Inner List
(RFC 8941 Section 3.1.1).
Signature-Input: label=(component identifiers)optional parameters, label=(component identifiers)optional parameters, ...
Labels can be assigned arbitrarily; however, any label present in the
Signature HTTP field MUST also be present in the Signature-Input
HTTP field.
The following example, excerpted from RFC 9421 Section 4.3,
shows an HTTP request containing both the Signature and Signature-Input
HTTP fields.
POST /foo?param=Value&Pet=dog HTTP/1.1
Host: example.com
Date: Tue, 20 Apr 2021 02:07:55 GMT
Content-Type: application/json
Content-Length: 18
Content-Digest: sha-512=:WZDPaVn/7XgHaAy8pmojAkGWoRx2UFChF41A2svX+TaPm+AbwAgBWnrIiYllu7BNNyealdVLvRwEmTHWXvJwew==:
Signature-Input: sig1=("@method" "@authority" "@path" "content-digest" "content-type" "content-length");created=1618884475;keyid="test-key-ecc-p256"
Signature: sig1=:X5spyd6CFnAG5QnDyHfqoSNICd+BUP4LYMz2Q0JXlb//4Ijpzp+kve2w4NIyqeAuM7jTDX+sNalzA8ESSaHD3A==:
{"hello": "world"}
As RFC 9421 itself states, the specification is designed as a tool, and therefore additional requirements need to be defined according to the purposes of the application or profile when it is actually used. RFC 9421 Section 1.4 provides examples of such requirements. For instance, the following items are listed:
FAPI 2.0 HTTP Signatures, one of the FAPI 2.0 specification family, profiles RFC 9421 in order to apply HTTP message signatures to resource requests to the resource server and to resource responses from the resource server, and defines concrete requirements.
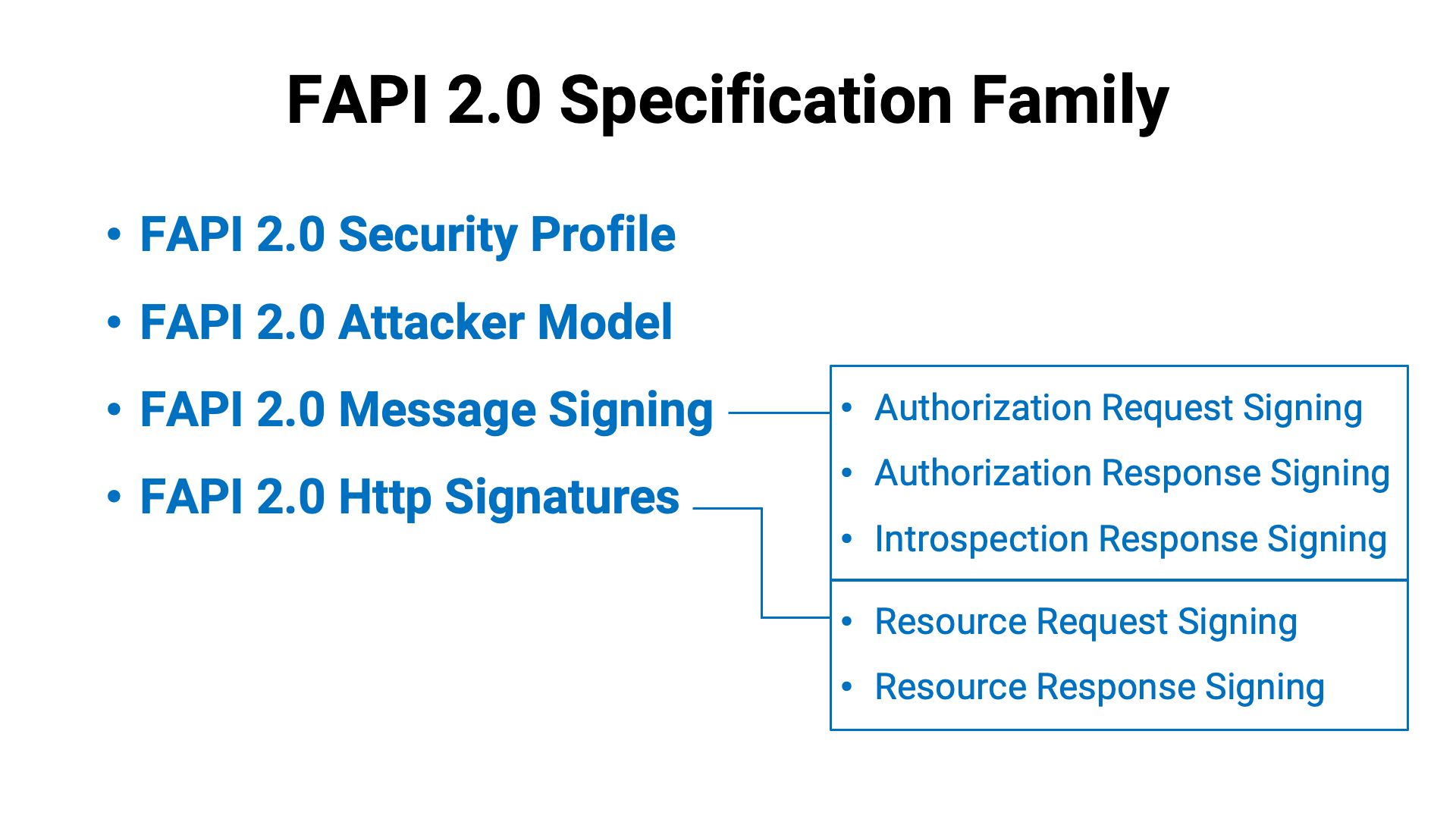
A summary of the specification is as follows. Note that, as the specification is still under development, it may be subject to change in the future.
| Request Signing | ||
|---|---|---|
| Components | "@method" |
|
"@target-uri" |
||
"authorization" |
||
"dpop" |
If DPoP is used. | |
"content-digest" |
If the request has a message body. | |
| Metadata Parameters | created |
|
tag |
The value is fixed to "fapi-2-request". |
|
| Response Signing | ||
|---|---|---|
| Components | "@method";req |
|
"@target-uri";req |
||
"authorization";req |
||
"dpop";req |
If DPoP is used. | |
"content-digest";req |
If the request has a message body. | |
"@status" |
||
"content-digest" |
If the response has a message body. | |
| Metadata Parameters | created |
|
tag |
The value is fixed to "fapi-2-response". |
|
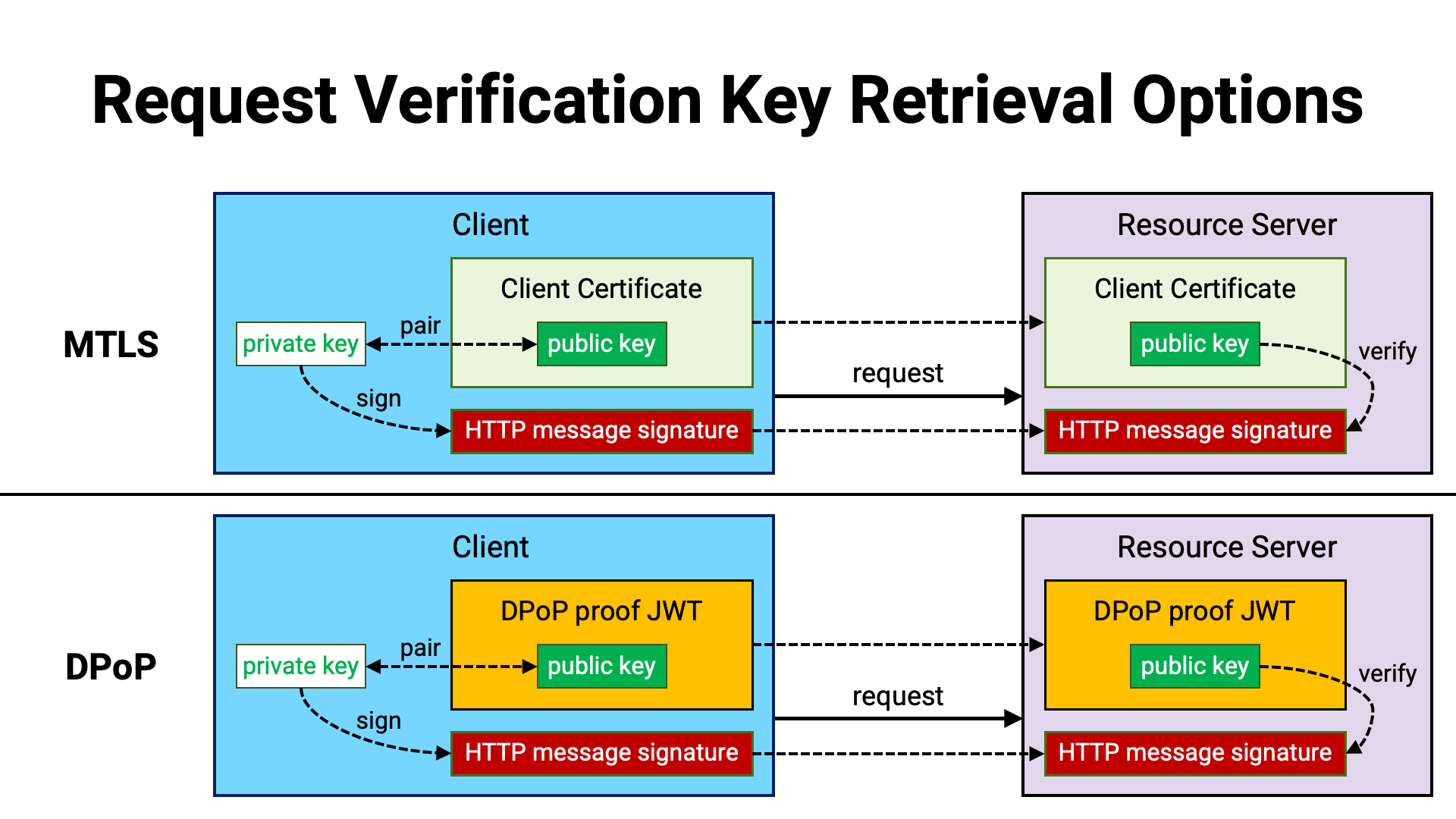
When using the FAPI 2.0 HTTP Signatures specification, the FAPI 2.0 Security Profile specification also applies, and therefore sender-constrained access tokens using either MTLS or DPoP are employed for resource requests.
In both the MTLS and DPoP cases, the client application’s public key is conveyed to the resource server. With this technical property in mind, by introducing the convention that “the HTTP request is signed with the private key paired with the public key bound to the sender-constrained access token,” the verification key retrieval problem mentioned in the “Verification Method” can be solved.
The advantage of this solution is that the verification key can be obtained solely through approved standard specifications (RFC 8705 and RFC 9449). This avoids reliance on non-standard, implementation-specific methods, thereby improving interoperability.
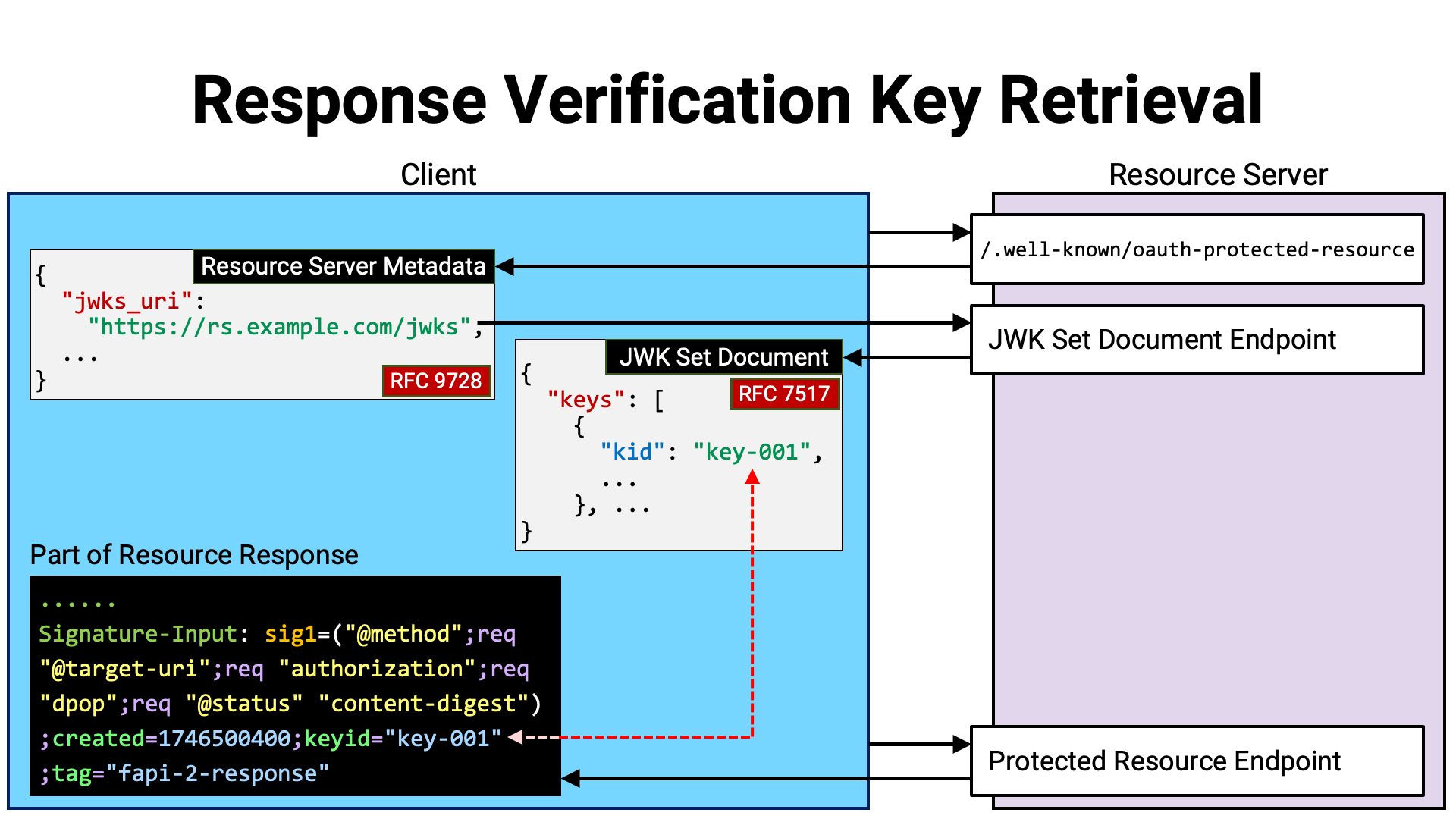
In order for a client application to verify the HTTP message signature of a resource response, it must obtain the verification key provided by the resource server.
Compared to the client application providing the verification key, the provision of the verification key by the resource server can be realized in a straightforward manner. Just as authorization servers and OpenID providers do, the resource server can publish a JWK Set document (RFC 7517) and include within it the verification key used for verifying HTTP message signatures.
The location of the JWK Set document can be indicated by the jwks_uri
property within the resource server metadata (RFC 9728) published
at /.well-known/.
When providing verification keys via a JWK Set document, it is advisable to
assign the same key identifier to both the key (JWK) and the HTTP message
signature, so that the verification key can be identified among multiple keys.
The key can be associated with a key identifier using the kid property
(RFC 7517 Section 4.5), and the HTTP message signature can be
associated with it using the keyid parameter
(RFC 9421 Section 2.3).
The scope (RFC 6749 Section 3.3) of an access token represents the coarse-grained permissions associated with that access token.
In order to express more fine-grained permissions, some authorization server implementations introduced a mechanism in which scope names are given structure, with parts of the scope name treated as variables. Such mechanisms are referred to as “parameterized scopes” or “dynamic scopes”. Of course, there is no interoperability across implementations.
That said, packing information into scope names is, frankly, a bad practice.
To improve this situation,
RFC 9396 OAuth 2.0 Rich Authorization Requests (commonly known as
RAR) was developed. The RAR specification defines the
authorization_ JSON array as a general mechanism for
representing permissions in a structured way.
Each element of the authorization_ JSON array is a
JSON object (hereafter referred to as a RAR object). The only mandatory
property that a RAR object must have is type. This type property indicates
the structure of the RAR object.
RFC 9396 itself does not define values for the type property.
The values to be used are determined independently by applications or profiles.
For example, the OpenID for Verifiable Credential Issuance (OID4VCI)
specification defines the value openid_. Below is
an example of an authorization_ array excerpted from
that specification.
[
{
"type": "openid_credential",
"credential_configuration_id": "UniversityDegreeCredential"
}
]
The RAR specification defines, in addition to the type property, the
following properties. Whether or not to use them is optional:
locationsactionsdatatypesidentifierprivilegesAs illustrated in the usage example from the OID4VCI specification mentioned
earlier, applications and profiles may also add their own custom properties to
RAR objects. Below is an example of an authorization_
array excerpted from RFC 9396, which makes use of top-level
properties such as geolocation and currency that are not defined in
RFC 9396.
[
{
"type": "photo-api",
"actions": [
"read",
"write"
],
"locations": [
"https://server.example.net/",
"https://resource.local/other"
],
"datatypes": [
"metadata",
"images"
],
"geolocation": [
{
"lat": -32.364,
"lng": 153.207
},
{
"lat": -35.364,
"lng": 158.207
}
]
},
{
"type": "financial-transaction",
"actions": [
"withdraw"
],
"identifier": "account-14-32-32-3",
"currency": "USD"
}
]
According to the RAR specification, the authorization_
parameter can be used anywhere the scope parameter is available (provided the
implementation supports it). For resource servers, the most important
occurrences of the authorization_ parameter are in
introspection responses and in the payload of JWT access tokens.
The following is an excerpt from RFC 9396 Section 9.2. Token Introspection, showing an example of an introspection response.
{
"active": true,
"sub": "24400320",
"aud": "s6BhdRkqt3",
"exp": 1311281970,
"acr": "psd2_sca",
"txn": "8b4729cc-32e4-4370-8cf0-5796154d1296",
"authorization_details": [
{
"type": "https://scheme.example.com/payment_initiation",
"actions": [
"initiate",
"status",
"cancel"
],
"locations": [
"https://example.com/payments"
],
"instructedAmount": {
"currency": "EUR",
"amount": "123.50"
},
"creditorName": "Merchant123",
"creditorAccount": {
"iban": "DE02100100109307118603"
},
"remittanceInformationUnstructured": "Ref Number Merchant"
}
],
"debtorAccount": {
"iban": "DE40100100103307118608",
"user_role": "owner"
}
}
Cedar is a language for writing authorization policies (Cedar Policy Language Reference Guide). Authorization policies written in Cedar (hereafter, Cedar policies) can be used to determine whether to allow access to a resource.
One major advantage of Cedar is that it enables you to separate authorization logic from business logic. Cedar policies can be externalized and managed independently from business logic. In fact, there are commercial services available for managing Cedar policies (see Integrations).
Another major advantage of Cedar is that it allows authorization logic to be expressed with fine granularity. For example, you can write an authorization rule such as “If someone is Jane’s friend, they are allowed to view and comment on photos in Jane’s trip album.” Below is an example of a Cedar policy that represents this authorization logic, excerpted from the Example scenario in the Cedar Policy Language Reference Guide.
permit ( principal in Group::"janeFriends", action in [Action::"view", Action::"comment"], resource in Album::"janeTrips" );
Cedar policies can include when and unless clauses to specify the
conditions under which a policy applies. Within these conditions, you can use
comparison operators, logical operators, arithmetic operators, and more, giving
Cedar a high level of expressiveness.
permit ( principal, action == Action::"read", resource ) when { resource.owner == principal || resource.tag == "public" };
By associating scopes with an access token (RFC 6749 Section 3.3), it is possible to represent the coarse-grained permissions of that access token. Similarly, if we could associate Cedar policies with an access token, wouldn’t it be possible to represent the fine-grained permissions of that token?
One promising approach to realizing this idea is to represent Cedar policies as RAR objects.
When determining the details of how to represent them, the following considerations arise:
The original syntax of Cedar policies is unique. Should we embed the policy
in its original syntax within the RAR object, or should we convert it to
JSON format (JSON Policy Format) before embedding?
While the JSON format is highly compatible with RAR, it tends to be verbose
(particularly in expressing when / unless conditions), and most members
of the Cedar community are likely to prefer the original syntax.
Should both the original Cedar syntax and the JSON format be supported, or should we limit support to one of them?
If both formats are supported, how should the format in use be indicated?
Should the information be embedded in the value of the type property, or
should a separate property (e.g., format) be introduced?
Should a policy set be represented as a single RAR object, or should each
RAR object represent only a single policy? In the JSON representation of a
policy set shown in
“Representing a policy set with JSON”, a single
JSON object contains staticPolicies, templates, and templateLinks.
Should we follow this approach? And in the first place, is support for
templates necessary in the RAR context?
Might there be cases where something other than Cedar policies (e.g., Cedar
schemas) would need to be represented? If so, how should the value of type
be determined in anticipation of that possibility?
The following is an example of the “Cedar in RAR Object” specification.
| Specification Example of "Cedar in RAR Object" | |||
|---|---|---|---|
| Properties | type |
The value is fixed to "cedar-policy".
|
|
format |
OPTIONAL |
"cedar" (default) or "json".
|
|
policy_id |
OPTIONAL | Policy ID. JSON string. | |
policy |
REQUIRED |
Cedar Policy. If the value of the format property is
"cedar", this contains a single JSON string representing
a Cedar policy written in the original Cedar syntax.
If the value of the format property is "json",
this contains a JSON object representing a single Cedar policy written
in the JSON Policy Format.
|
|
| Entities | principal |
If a subject is associated with the access token (i.e., if the
introspection response or the JWT access token payload contains
a sub claim), then the principal entity is
User; otherwise, it is Client.
For a User entity, the value of the access token’s
sub claim is treated as its unique identifier. For
a Client entity, the value of the access token’s
client_id is treated as its unique identifier.
The elements of the access token’s groups,
roles, and entitlements claims
(RFC 9068 Section 2.2.3) are mapped to Group,
Role, and Entitlement entities,
respectively, and are set as parent entities of the
principal. If they follow
RFC 7643 Section 2.4, each element is a JSON object that
includes a value property (e.g.,
"groups").
The value of this value property is treated as the
unique identifier of the entity. If they do not follow
RFC 7643 Section 2.4, they are assumed to be JSON strings
(e.g., "groups"),
and the string value itself is treated as the unique identifier
of the entity.
|
|
action |
action entities are defined by the resource server.
|
||
resource |
resource entities are defined by the resource server.
|
||
| Context | time |
The current time expressed as the number of milliseconds elapsed since the Unix epoch. | |
access_token |
Information about the access token. It has the sub-properties
iss, sub, and client_id.
|
||
ip_address |
Client’s IP address. | ||
The following is an example of an authorization_
array written based on this specification. The first RAR object describes
a Cedar policy using the original Cedar syntax, while the second RAR object
describes a Cedar policy using the JSON Policy Format.
[
{
"type": "cedar-policy",
"format": "cedar",
"policy_id": "policy-0",
"policy": "permit (principal == User::\"12UA45\", action == Action::\"view\", resource);"
},
{
"type": "cedar-policy",
"format": "json",
"policy_id": "policy-1",
"policy": {
"effect": "permit",
"principal": { "op": "==", "entity": { "type": "User", "id": "12UA45" } },
"action": { "op": "==", "entity": { "type": "Action", "id": "view" } },
"resource": { "op": "All" }
}
}
]
Some of the APIs provided by a resource server may impose stricter security requirements than others. For example, it is common for a funds transfer API to require higher security than a balance inquiry API.
Among such security requirements, one possible requirement is that the user must undergo stronger authentication than usual when obtaining the access token.
If the user authentication performed when the presented access token was obtained does not meet the required criteria, the API would likely want to notify the client application of this fact and prompt it to re-obtain the access token. In such cases, the RFC 9470 OAuth 2.0 Step Up Authentication Challenge Protocol can be used.
The API can notify that the user authentication at the time of token
issuance did not meet the requirements by using the error code
insufficient_. The error response
can also include information about the requirements by using parameters such
as acr_ and max_.
Below is an example error response excerpted from RFC 9470.
HTTP/1.1 401 Unauthorized
WWW-Authenticate: Bearer error="insufficient_user_authentication", error_description="A different authentication level is required.", acr_values="myACR"
For more details on RFC 9470, please refer to “RFC 9470 OAuth 2.0 Step Up Authentication Challenge Protocol.”
At the OIDF, the AuthZEN Working Group is currently developing the Authorization API 1.0 specification.
At the core of this specification is the Access Evaluation API. When you provide this API with the necessary information to determine whether access should be granted, it returns the evaluation result as a boolean value. Below is an example request and response for this API.
{
"subject": {
"type": "user",
"id": "alice@acmecorp.com"
},
"resource": {
"type": "account",
"id": "123"
},
"action": {
"name": "can_read",
"properties": {
"method": "GET"
}
},
"context": {
"time": "1985-10-26T01:22-07:00"
}
}
{
"decision": true
}
The input parameters are the subject, resource, action, and context, while the output parameter is the evaluation result. Although these input and output components seem correct, my intuition is that the Access Evaluation API might only be implementable by a server that centrally manages all the input elements—handling both user management and resource management. It will be interesting to see what kinds of implementations emerge in the future.
At the time of the publication of RFC 6749 in 2012, which is the core specification of OAuth 2.0, the only mechanism available for API access control was scopes. Since then, various additional features have been introduced.
Among these, sender-constrained access tokens using MTLS or DPoP are particularly important, and FAPI 2.0 requires the implementation of either one. In April 2022, an incident occurred in which access tokens stolen from Heroku / Travis-CI were abused elsewhere (GitHub), highlighting the importance of sender-constraining mechanisms.
Authlete has contributed to the development of advanced security specifications such as RFC 9449 (DPoP), FAPI 2.0 Security Profile, and FAPI 2.0 Http Signatures (its authorship is listed in the specifications). Authlete also provides commercial implementations of these specifications.
For those seeking expertise in API protection or commercial implementations, please contact us.

