この記事は、2025年12月11日に開催された 「Authlete Customer and Partner Meetup 2025」 のプレゼンテーションの抜粋です。株式会社 Jij Software Development Team ソフトウェアエンジニア 坂本慶己氏に量子コンピューターや AI を活用した B2B SaaS プラットフォームに Authlete をご採用いただいた理由と、Authlete を活用した認証・認可基盤の開発についてお話しいただきました。

Jij の坂本と申します。株式会社JIJ (Jij)でソフトウェアエンジニアを務めております。福岡出身で、大学院卒業後にスタートアップである Jij に入社しました。ソフトウェア開発全般を担当しており、バックエンド開発、CI/CD、クラウドインフラの設計・運用に加え、昨年からは認証・認可基盤の設計および運用も担当しています。好きなプログラミング言語は関数型言語や静的型付け言語で、Clojure が最も好きです。普段は Rust や TypeScript を用いて開発しています。

Jij は量子コンピューターや AI を用いた大規模な最適化計算を行い、困難な課題を解決することを目指す企業です。社名の由来は量子力学の「イジングモデル」における、スピン(アップスピン、ダウンスピン)や磁気作用を数式で表す際の係数「Jij」から来ています。約40名ほどの小規模な会社ですが、様々な企業と研究開発に取り組んでいます。
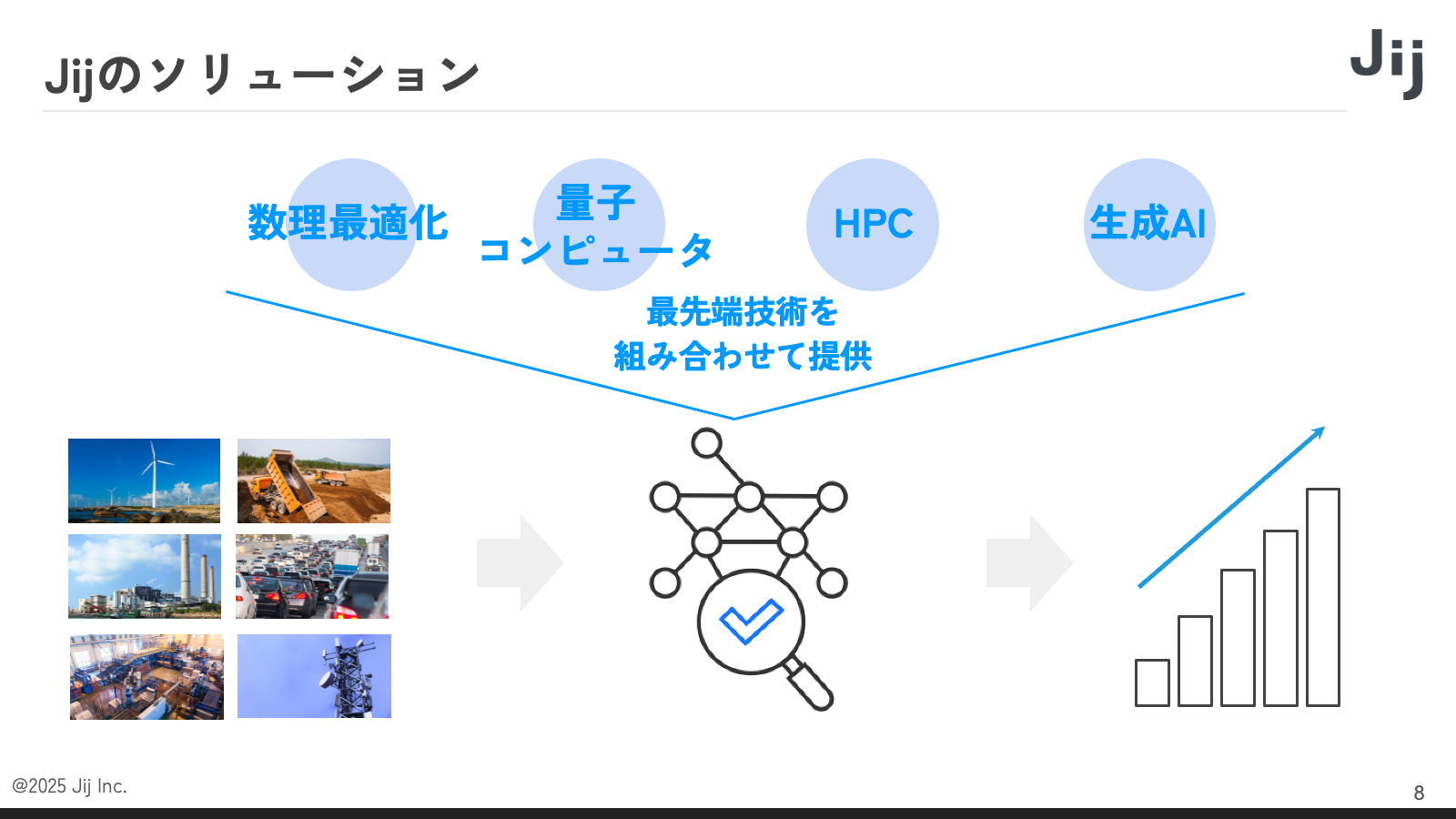
Jij の主な事業は最適化事業です。エネルギー、製造、交通、物流など、インフラストラクチャー領域における B2B 向けのサービスを提供しています。エネルギー会社や発電所、新材料開発、鉄道など、重厚長大なインフラメーカーへの提供実績があります。具体例としては、化学薬品メーカーさまとの共同プロジェクトにおいて、DX 推進や製造現場におけるシフト最適化、さらには化学物質材料の最適な組み合わせを数式化して計算を行うことで、製造計画の高速化を実現しました。
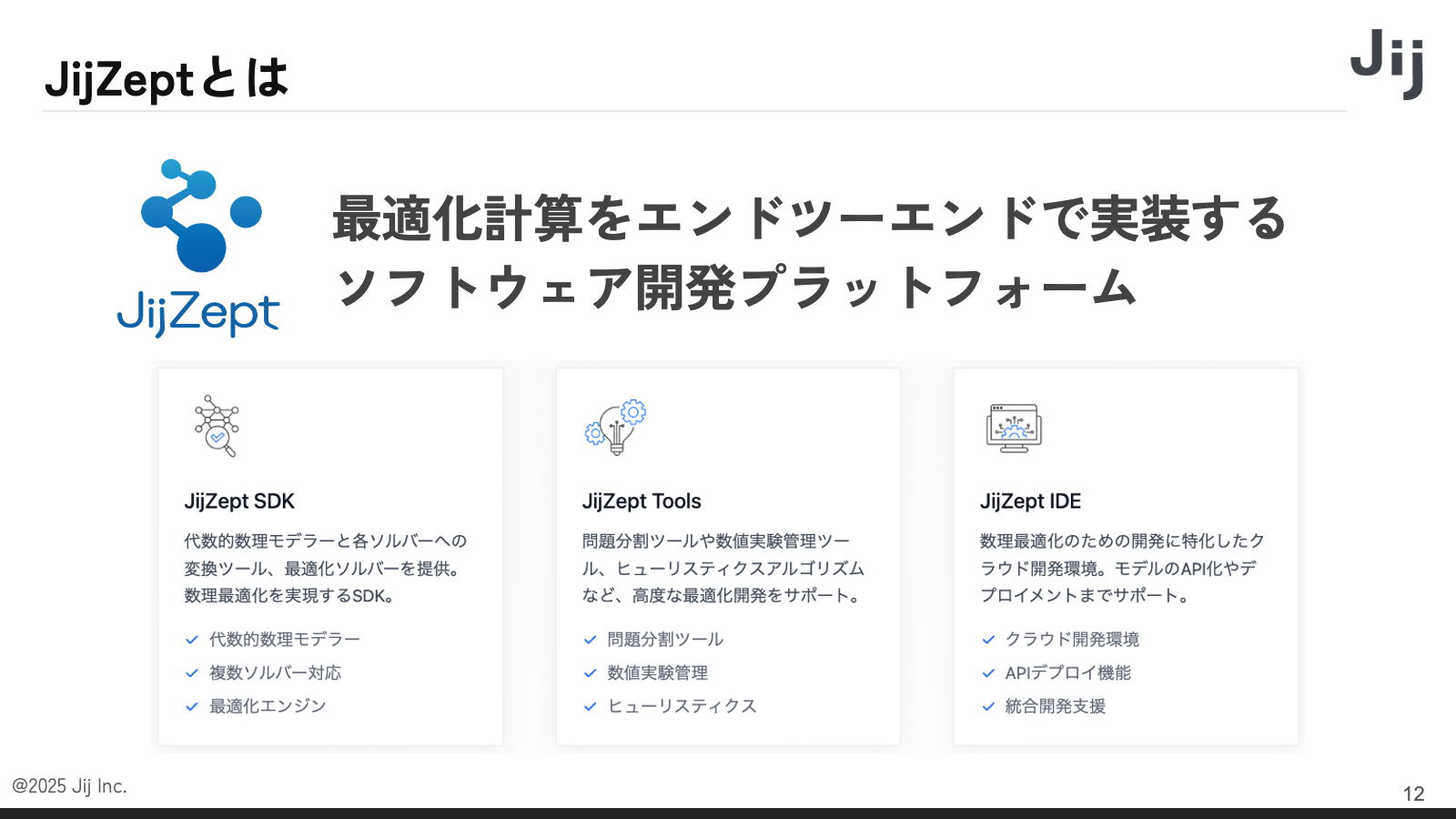
Jij では SaaS も提供しています。具体的な SaaS プラットフォームには、「JijZept SDK」「JijZept Tools」「JijZept IDE 」などがあります。このうち、ユーザーがログインして数理最適化を実行する「IDE」の環境において、Authlete のサービスを利用しています。

Jij のサービス提供先はインフラや基幹業務を担う企業が中心で、中でも研究開発室や事業推進本部など、セキュリティ要件が非常に厳しい部門で利用されています。そのため、セキュリティチェックシートへの対応が大きな課題となっていました。具体的には、アクセス先ドメインのリスト化(許可されたドメインのみ通信可能)、許可されたドメインへのプロキシ経由の通信の強制、そしてデータの所在地を全て日本国内に限定することなどが求められます。また、国外にデータが出る場合は、その送信先や使用サービスを明示する必要があります。
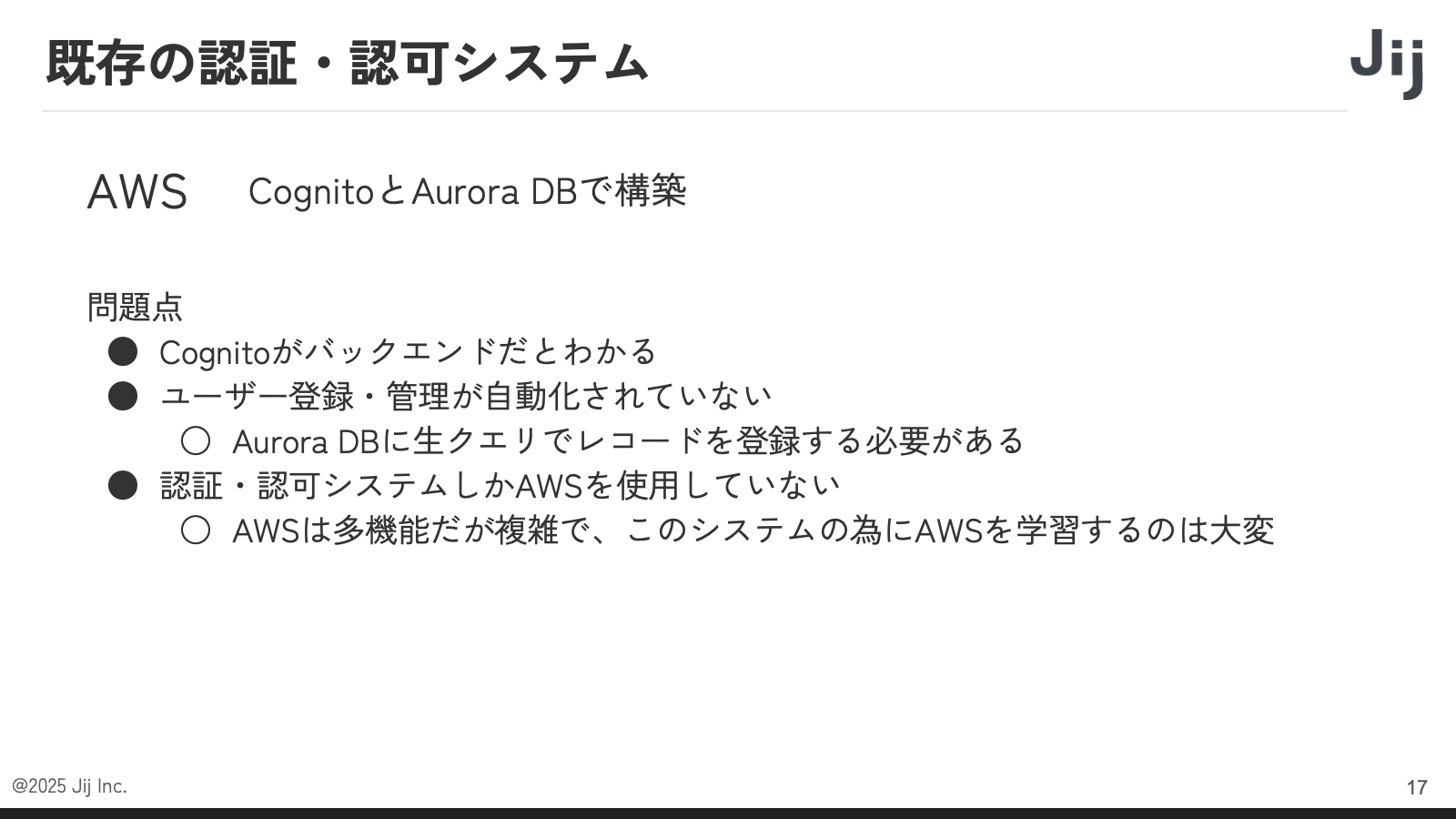
以前は、AWS の Cognito と Aurora DB を使用していました。しかし、バックエンドが Cognito であるため Cognito サーバーへのアクセス要件をセキュリティチェックシートに記載する必要がありました。さらに、ユーザー登録・管理をアドホックに構築していたため、Aurora DB に生クエリでレコードを登録し、Cognito 側のデータベースと同期するためのバッチ処理を組むなど、システムが複雑化していました。また、他のシステムでは AWS を使用せず、別のクラウドサービスを使っており、認証・認可システムのためだけに AWS を利用していました。
AWS は多機能である一方、複雑で使いこなすのが大変で、認証・認可のためだけに AWS のデーターベースの使い方を学んだり、サポート費用を負担することは適切ではないと判断しました。そこで、新しい基盤は Google Cloud と Authlete で構築することにしました。
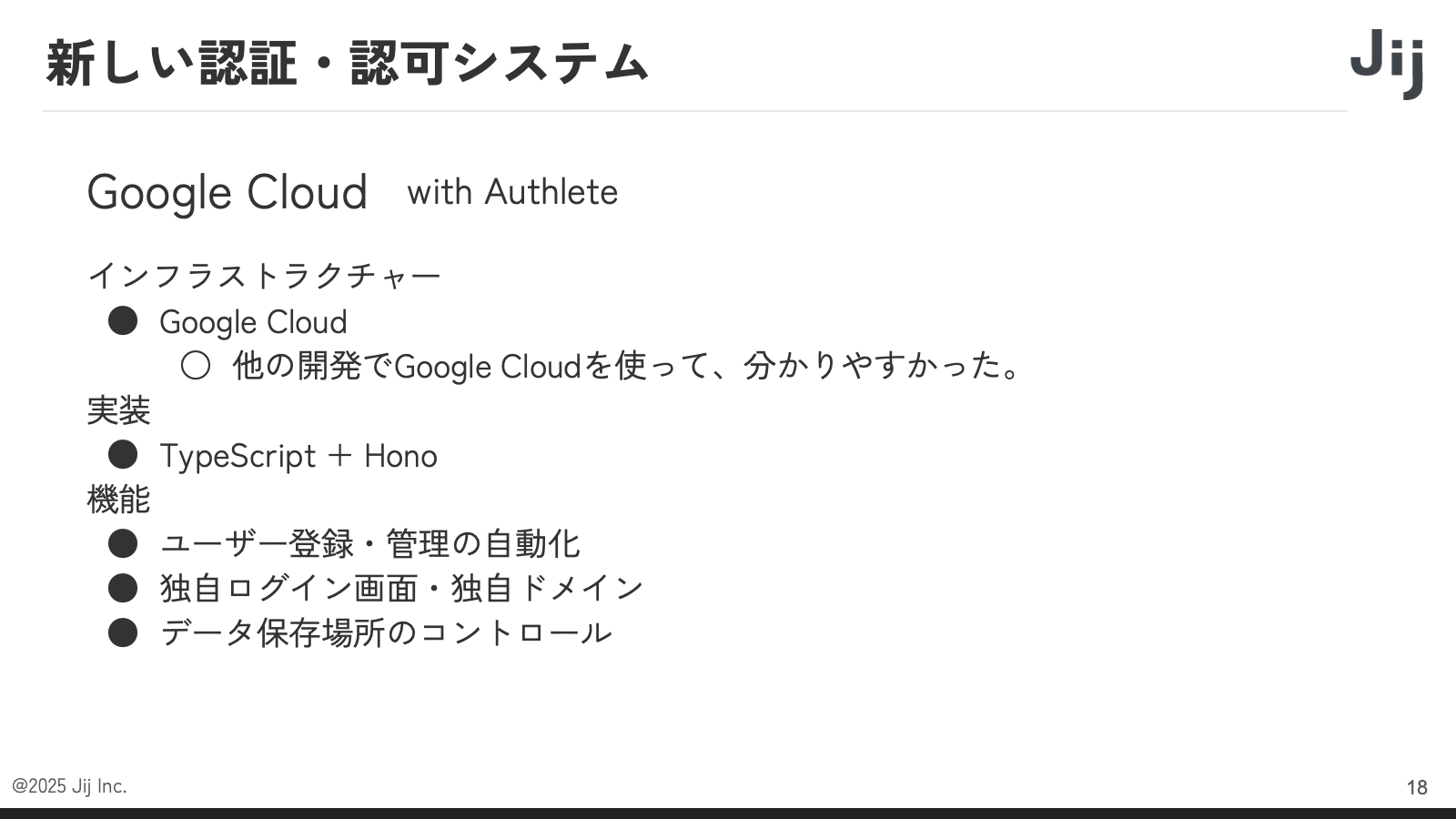
インフラストラクチャーとして Google Cloud を選んだ理由は、他の開発プロジェクトで利用実績があり、使いやすかったことに加え、弊社はスタートアップで人的リソースが限られているため、フルマネージドなサービスを利用したかったためです。
実装には TypeScript と Hono を採用し、機能要件としては、ユーザー登録や管理の自動化に加え、独自ログイン画面と独自ドメインの実装を必須としました。これらを用意しない場合、セキュリティチェックシートにどのドメインでアクセスしているかを記載する必要があるためです。また、データ保存場所については、現在は Google Cloud の Alloy DB と Cloud SQL を利用し、すべて日本リージョンに設定しています。これにより、セキュリティシート対応を大幅に簡素化することができました。

Authlete を採用した最大の理由は、自由にシステム構築ができる点にあります。包括的なソリューションは多く存在しますが、それらを導入する場合、ソリューションに合わせたシステムを作る必要があります。Jij は、B2B のスタートアップであり、量子計算や推論結果を提供するという特殊な使用用途を持つプラットフォームを提供しているため、高い拡張性が求められました。
さらに、Authlete は、OAuth/OpenID Connect (OIDC) の仕様を忠実に実装しているため、顧客に説明しやすいという利点があります。また、データの保存場所、ログイン方法、パスワード設定の要件などもすべて弊社で設計することができます。顧客が触れるログインやユーザー登録の部分を完全に Jij 側でカスタマイズし、フル実装することができるため、B2B 顧客の様々な要望に応えることができます。
また、スタートアップである弊社には、Authlete は非常によくフィットするサービスでした。スタートアップでは、最初から全機能を実装するのは人的リソースの観点からも難しく、会社の経営方針が今後どう変わるのか予測不可能な面もあり、必要な時に必要な機能だけを実装し、将来的に段階的に拡張していきたいという要望があります。Authlete は、機能が API コンポーネントとして提供されており、管理画面で後から特定の機能を有効化するだけで機能追加が可能なため、この柔軟性が非常に役立ちました。

一方で、Authlete は多様な API を提供しており、かつカスタマイズ性が高いため、どの機能を使うべきか、API をどう呼び出すべきか、Authlete の役割と自社実装の分担をどうするか、といった悩みを設計段階で抱えました。そこで、Authlete に詳しいパートナーとして Instiny の豊島さんをご紹介いただき、豊島さんの協力を得ながら実装を進めました。

Instiny の支援を受けつつ、私1人で2024年9月頃から要件定義や学習を開始し、12月から1月初旬にかけて実質的に完成したため、実際の開発期間は約3〜4ヶ月となりました。いちから要件定義を行い、開発途中のピボットにも対応した上でこの期間で完成させたことを考慮すれば、十分に早いスピードで構築できたと考えています。
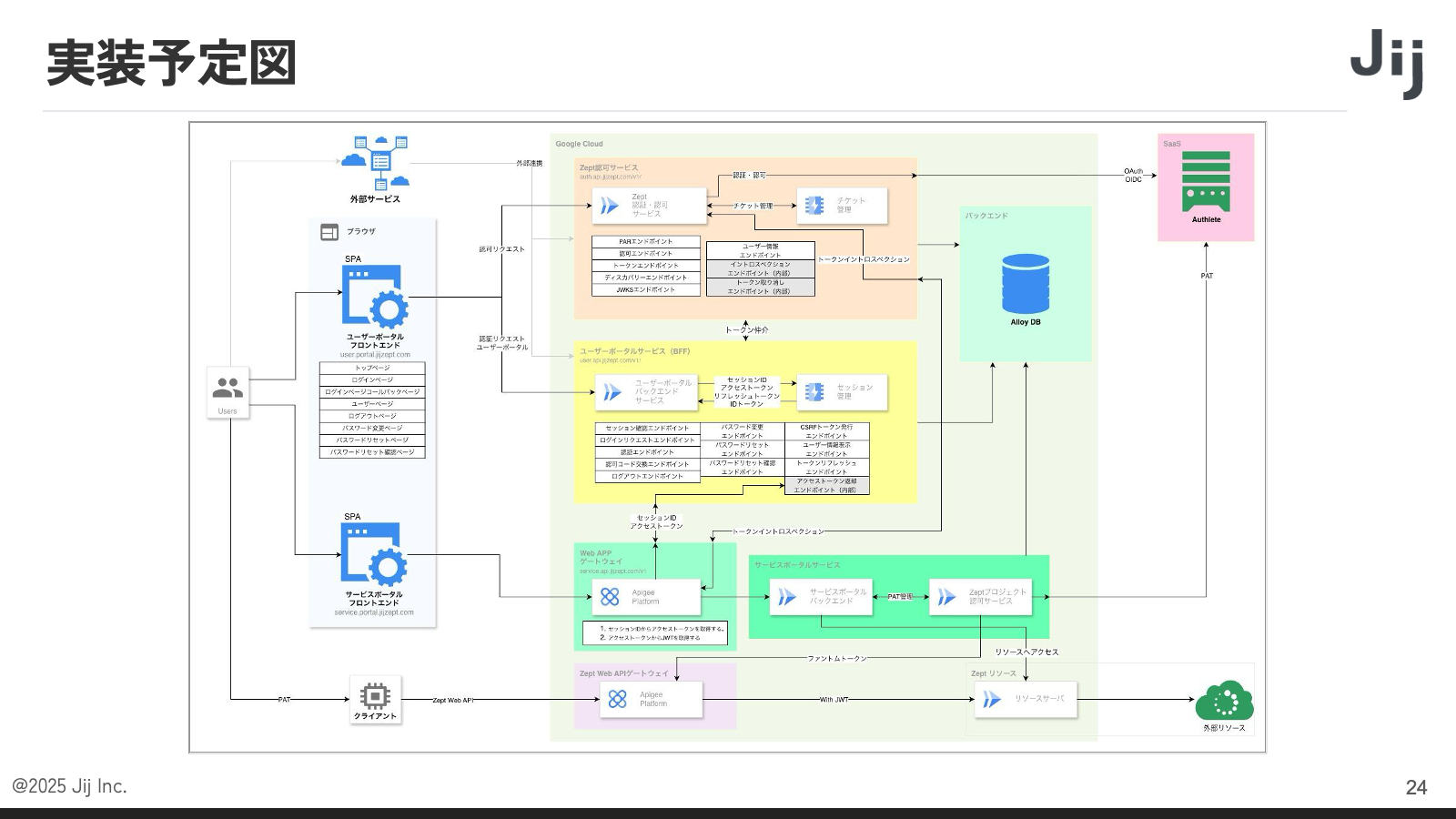
実装予定図は、ブラウザベースのフロントエンド、ポータル、そして Apigee で構成されています。基本的にはフルマネージドで構成したかったため、Alloy DB、Cloud Run などを活用しています。

実質3〜4ヶ月という短期間で実装を完了できたのは、Instiny の支援があったからです。Authlete の API は多機能ですが、選定に迷ったため、今回の要件においてどの API を利用し、どのようなパラメータを設定すべきか、一緒に整理していただきました。また、ログインフローについても、PAR (Pushed Authorization Requests) から認可リクエスト、認証画面、トークン発行へと至る標準的な流れを実装レベルで具体化することができました。

アーキテクチャに関しては、SPA と BFF の採用を検討しましたが、アクセストークンを BFF のみで保持させることでトークン詐取のリスクを軽減できるため、BFF を採用しました。構成の複雑化を避けるため、DPoP の採用は見送りましたが、将来的に BFF 以外のクライアントとの連携が増えた場合は、Authlete の機能を用いてクライアントごとに DPoP を必須とすることができる見込みです。

また、Authlete のパラメータ数が多いため、全ての型定義を行うのは非現実的であると判断し、要件上必須となるフィールドに絞って Zod で型付けを行いました。この範囲の設計についても、Instiny の支援を受けました。

Instiny には、セキュリティレビューにおいても、トークンエンドポイントのキャッシュ抑止ヘッダーやパスワードリセットのフローなど、一つずつご確認いただきました。そのため、安心してリリースを迎えることができました。
実装には TypeScript を採用しました。以前は Python で Web サービスを構築していましたが、静的解析の支援が弱く、規模が拡大するにつれて変更が困難になるという課題がありました。認証・認可は仕様とデータ構造が厳密に定義されているため、静的型付けの利点を活かすことができます。また、Authlete のリクエストおよびレスポンスについても Zod を用いて型定義をしています。

今回実装するシステムは「認証・認可専用の REST API」であったため、SSR やフルスタックな機能は不要でした。フレームワークについては、Express や Nest.js も検討しましたが、TypeScript ファーストでありコンパクトなフレームワークである Hono が適していると判断しました。Hono はシンプルで、認証・認可専用の API サービスと非常に相性が良いという利点もありました。

実装においては、Hono、Zod、OpenAPI を組み合わせ、認証・認可に関わるエンドポイントごとにスキーマを定義することで、コンパイル時にエラーを検出できる仕組みを構築しました。認証・認可フローに変更がある際も、まずスキーマを修正することで影響範囲が明確化され、開発者の負担を軽減できるという利点もあります。

スタートアップにありがちな話ではありますが、連携予定であった既存サービスを終了し、その代わりに、ログインするだけですぐに開発ツールを利用できる新しい環境「JijZept IDE」を提供することになりました。その時点で、開発開始から2ヶ月以上が経過していました。

ピボットによって連携先のサービスが変更されることになりましたが、認証・認可側は、Authlete で OAuth 2.1 や OIDC の標準的なエンドポイント一式を実装していたため、基本的には繋ぎ先の変更とクライアントの追加のみで、迅速に対応することができました。
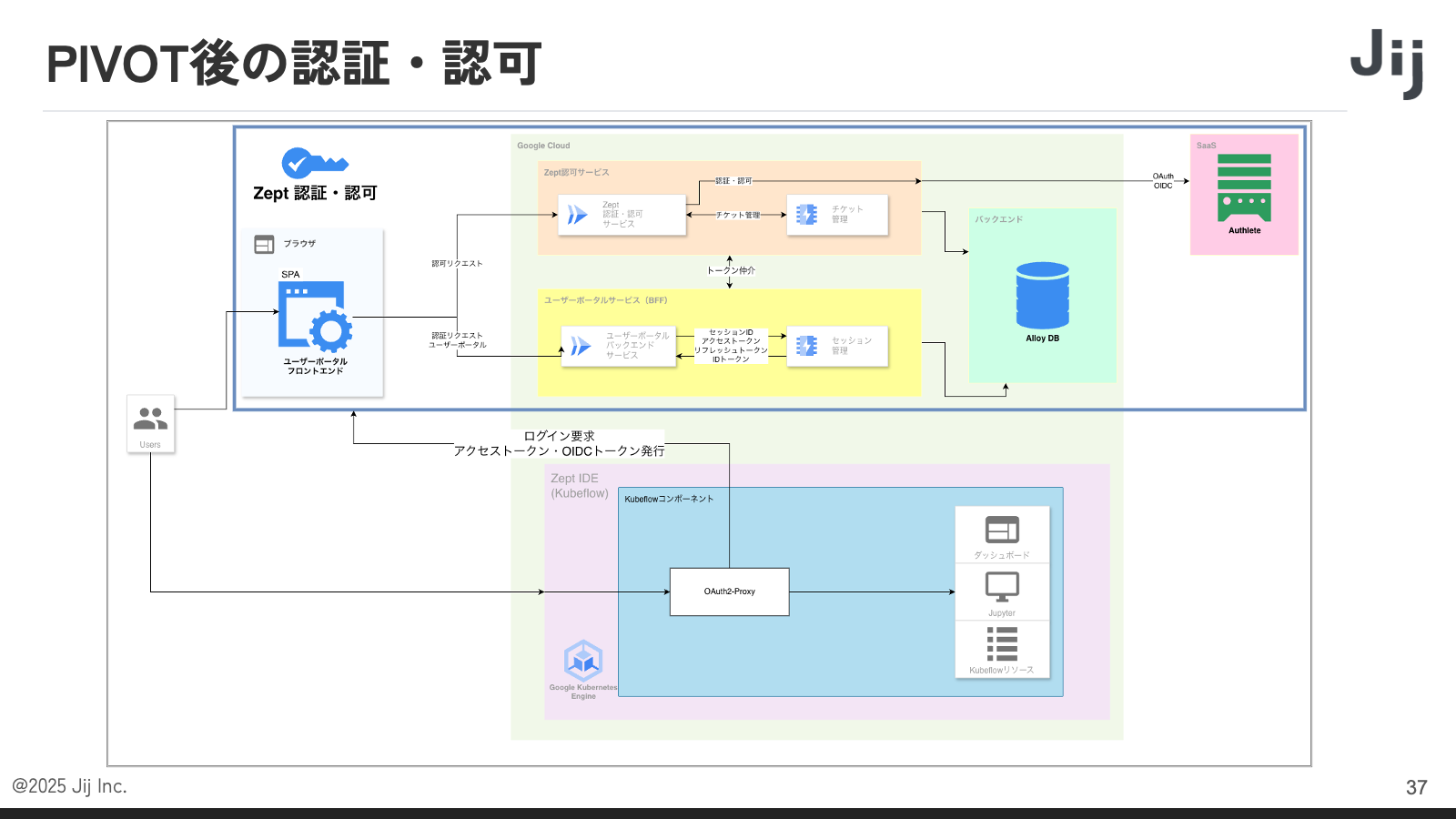
ピボット後の構成です。認証・認可側の変更点はありません。JijZept IDE 側は Kubeflow を採用しており、GKE(Google Kubernetes Engine)上で動く Jupyter Notebook 環境があります。認可処理を行うリバースプロキシーには OAuth2 Proxy を使用しています。
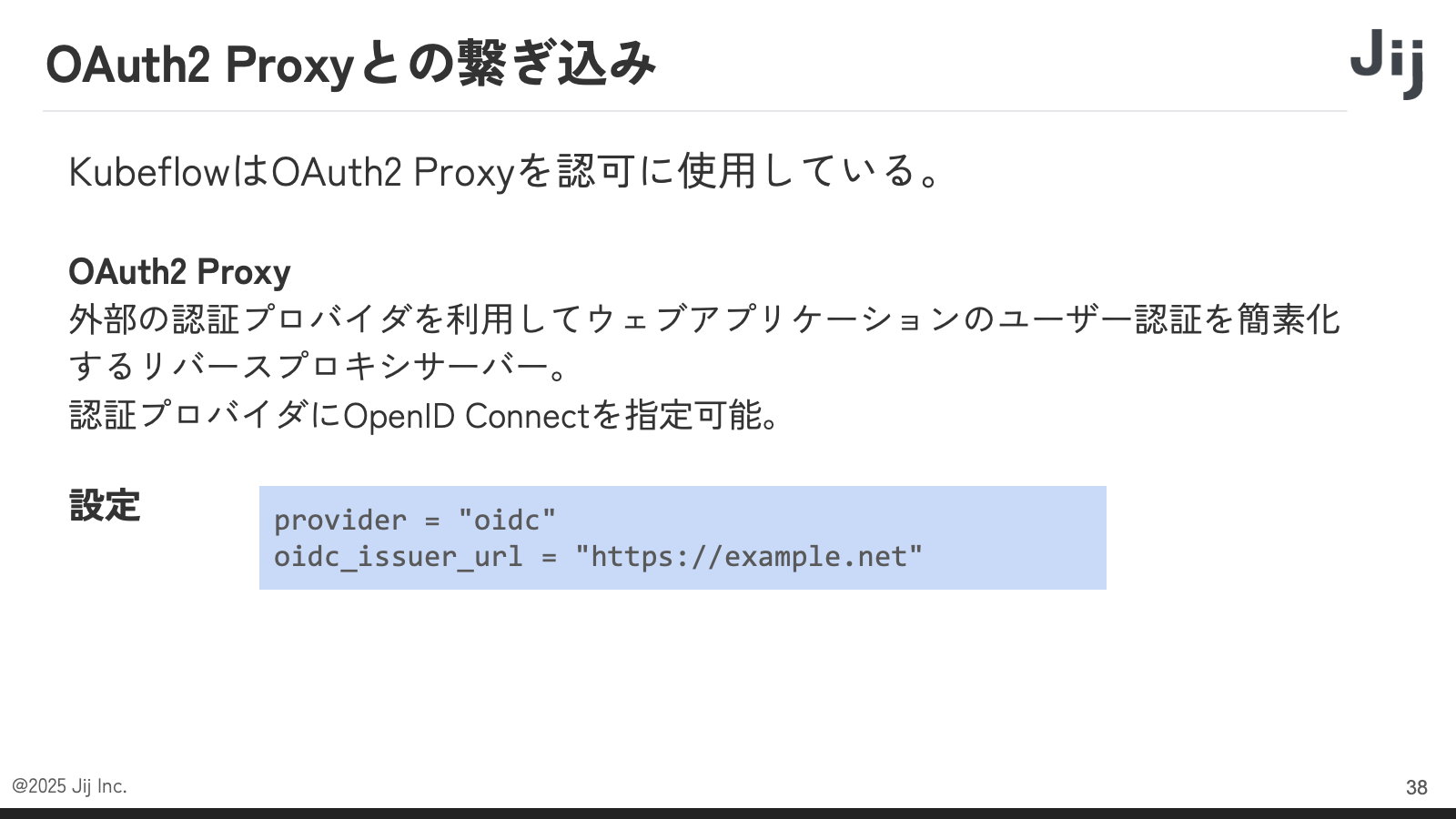
OAuth2 Proxy は、Web アプリケーションの前に置くことでユーザー認証を簡素化してくれるリバースプロキシです。ここで、私たちの基盤が標準仕様に準拠していたことが功を奏しました。OAuth2 Proxy の設定に、認証・認可基盤の発行者 URL(issuer)を書き込むだけで、基本的な繋ぎ込みは完了しました。これが仕様準拠の真骨頂です。

ただし、実際には小さな課題も発生しました。弊社では PA/BFF クライアント向けに「PAR+認可コードフロー」を使うことにしたのですが、OAuth2 Proxy 側がまだ PAR に対応していなかったのです。しかし、ここでも Authlete の柔軟性に救われました。Authlete の設定画面から、クライアント単位で『PAR 必須』のフラグを個別に制御することができたのです。SPA クライアントと OAuth2 Proxy とで異なる認可フローを、一つの認証・認可基盤で、安全かつスマートに共存させることができました。

JijZept IDE の提供プランには、複数顧客で Kubernetes クラスターを共有する「プールモデル(Standard プラン)」と、顧客企業専用に完全に分離されたクラスターをご用意する「サイロモデル(Premium/Enterprise プラン)」の2種類があります。
サイロモデルでは1つのクラスターを1つのクライアントとして扱います。Authlete 3.0の新しいダッシュボードは多数のクライアント設定が非常に見やすく整理されており、オペレーションミスを防ぐ上でも大きな役割を果たしています。

実際の設定イメージです。OAuth2 Proxy 側で Authlete を OIDCプロバイダーとして登録しています。
具体的にどのユーザーがどのリソースにアクセスできるかの最終判定は、Authlete から発行されるアクセストークン、あるいは ID トークンに含まれる Group クレームを用いています。プールモデルではこのクレームを見て論理的なデータ分離を、サイロモデルではそのユーザーがそのサイロにログインする権限があるかを、それぞれ判断します。インフラ構成がどれほど複雑になっても、認可のロジックはこの「Group クレーム」一つに集約されます。この設計のシンプルさが、システムの高い保守性を担保しています。
ここからは、さらなる進化を遂げた Authlete 3.0への移行についてお話しします。
まずうれしかったのが、Google SSO への対応です。Authlete 2.x では、管理者アカウントのログイン ID とパスワードをチーム内で共有せざるを得ないリスクがあり、誰がいつ設定を変更したのかという追跡性にも課題がありました。3.0からは個人の Google Workspace アカウントでログイン可能になり、退職者の権限削除も即座に行えます。

新たに導入された Organization 機能も、チーム運用の容易化に役立っています。現在は Admin と Viewer というシンプルな2択ですが、将来的にはサービスやクライアント単位でのより細かな権限設定が実装されることを期待しています。
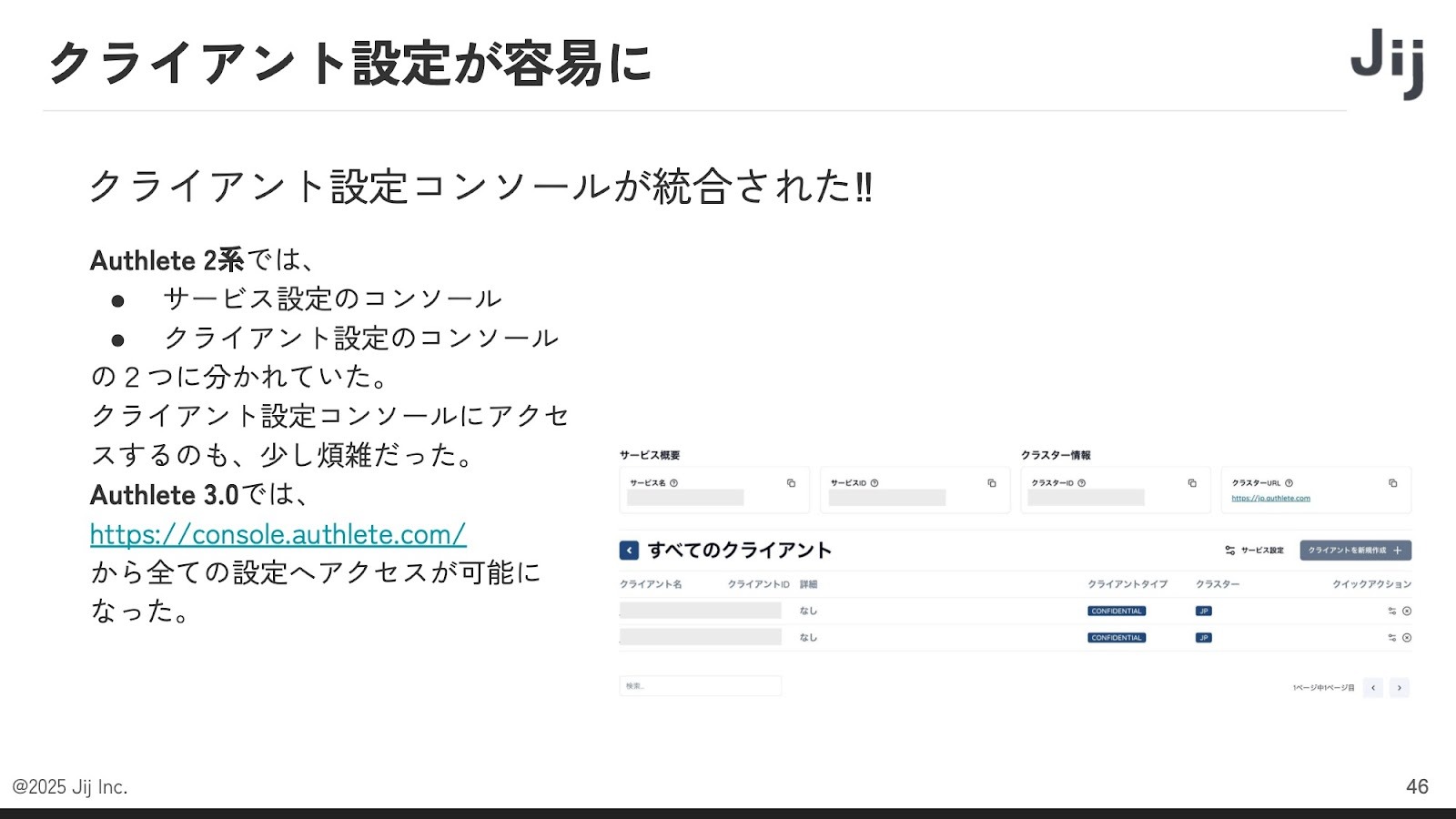
3.0になって最も大きかった進化が、管理コンソールの統合です。以前はサービス設定とクライアント設定が分かれており、またクライアント設定のコンソールへの動線が若干面倒になっていました。Authlete 3.0ではすべての設定が一つの URL、一つの画面からアクセス可能です。

もちろん、新バージョンへの移行初期には小さな不具合に遭遇したこともありました。しかし、そこで何よりも心強かったのが、Authlete さんの優れたサポート体制です。私たちの問い合わせに対して非常に丁寧、かつ迅速に対応いただき、ときには川﨑さまが対応してくれました。
最後に、今後の展望についてお話しさせていただきます。
今、AI は単に質問に答える存在から、「エージェント」へと進化しています。自律的にツールを選び、外部のソルバーやデータベースを叩いて課題を解決するエージェントが複雑なリソースを扱うようになると、「この AI エージェントは、この機密データにアクセスする権限があるか?」という認可の重要性は、人間を対象とした時よりも遥かに増大します。AI が自律的に動き回る世界の安全性は、正しき認証・認可という基盤の上にしか成立しないのです。

AI の進化スピードは、これまでの開発サイクルとは次元が違います。機能追加や連携先が刻々と変わっていきます。その中で、認証・認可基盤がボトルネックになってはいけません。だからこそ、今後の Authlete には、API リファレンスの充実、クライアントライブラリの使いやすさ向上、モック・テストの容易化を期待しています。

まとめです。まず第一に、スタートアップであっても、Authlete を活用することでエンタープライズ水準の壁を越えることができました。第二に、OAuth/OIDC 仕様を忠実に実装したことが、ピボットに対応する最強の力になりました。そして最後に、AI や MCP という新たな時代に向けて、より開発者フレンドリーな Authlete に期待しています。
.png)


